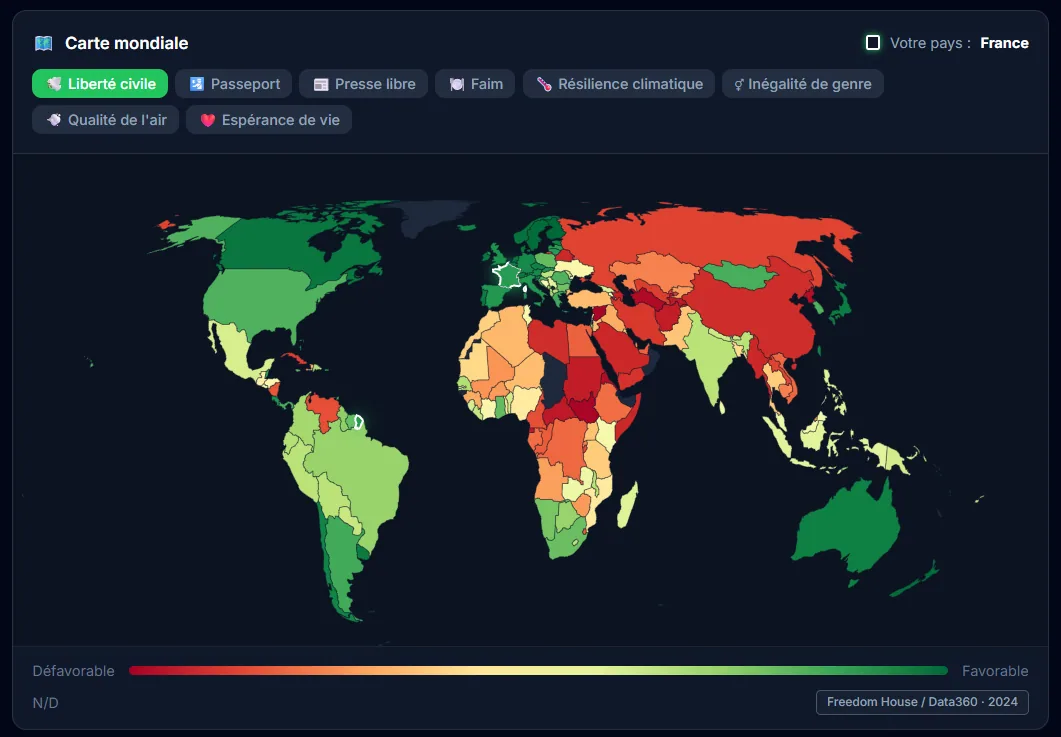
Tom LEFRERE · Data Scientist & Chef de projet IA
Des données.
Un signal.
Data Scientist au Ministère des Armées. Je transforme des datasets complexes en décisions lisibles, modélisation, explicabilité, IA appliquée.
ProjetsPortfolio · 28 projets
Chaque ligne de code
raconte quelque chose.
Data, web, expérimentations. Clique une carte pour ouvrir le projet sans quitter la page.
Reset Pack, réinstaller Windows en une commande

tom-lefrere.fr, mon site personnel en quatre vies

Esport Stats, une petite enquête data sur les scènes pros
Answer, un question answering sur documents
Animations Manim

BestPick, un recommandateur de champions pour LoL
Discord Recap, mon récap annuel reconstitué à ma sauce

Divine Simulation, des IA qui jouent aux dieux dans WorldBox
How Am I Lucky, une visualisation de la chance par les chiffres
Home Assistant × Claude, la domotique augmentée par l’IA
LoL Predict, une prédiction de matchs par ML
Mathelearning, une plateforme d’apprentissage des maths
Programme Maire, un test de compatibilité pour les municipales
Visualisation de données YouTube
Conscious, une application anti-gaspillage alimentaire
Opinion Mining, une analyse de sentiments sur du texte

GetSubscribedChannels, un export des chaînes YouTube
Legermain, un site vitrine d’artisan

Any%English, quelle part de YouTube je regarde en anglais ?

DofusClassSelector, une analyse du ladder Dofus

LunaSleep, la lune influence-t-elle ma qualité de sommeil ?
Big4Craft, un site de tournoi Minecraft monté en urgence
Université Populaire de l’Indre, une plateforme de cours
ExamApp, la planification des examens universitaires

Overbet, des paris amicaux sur l’esport Overwatch
Domopack, un configurateur de maison connectée
GesPatApp, la gestion d’un centre de santé en Java
DreamTeam, un journal de bord de projet terminal
- 01
Reset Pack, réinstaller Windows en une commande
Actif 2026 - 02
tom-lefrere.fr, mon site personnel en quatre vies
Actif 2026 - 03
Esport Stats, une petite enquête data sur les scènes pros
Terminé 2026 - 04
Answer, un question answering sur documents
Terminé 2026 - 05
Animations Manim
Terminé 2026 - 06
BestPick, un recommandateur de champions pour LoL
Terminé 2026 - 07
Discord Recap, mon récap annuel reconstitué à ma sauce
Terminé 2026 - 08
Divine Simulation, des IA qui jouent aux dieux dans WorldBox
Actif 2026 - 09
How Am I Lucky, une visualisation de la chance par les chiffres
Actif 2026 - 10
Home Assistant × Claude, la domotique augmentée par l’IA
Terminé 2026 - 11
LoL Predict, une prédiction de matchs par ML
Terminé 2026 - 12
Mathelearning, une plateforme d’apprentissage des maths
Terminé 2026 - 13
Programme Maire, un test de compatibilité pour les municipales
Terminé 2026 - 14
Visualisation de données YouTube
Terminé 2023 - 15
Conscious, une application anti-gaspillage alimentaire
Actif 2022 - 16
Opinion Mining, une analyse de sentiments sur du texte
Actif 2022 - 17
GetSubscribedChannels, un export des chaînes YouTube
Actif 2022 - 18
Legermain, un site vitrine d’artisan
Actif 2022 - 19
Any%English, quelle part de YouTube je regarde en anglais ?
Terminé 2021 - 20
DofusClassSelector, une analyse du ladder Dofus
Terminé 2021 - 21
LunaSleep, la lune influence-t-elle ma qualité de sommeil ?
Terminé 2021 - 22
Big4Craft, un site de tournoi Minecraft monté en urgence
Actif 2021 - 23
Université Populaire de l’Indre, une plateforme de cours
Terminé 2021 - 24
ExamApp, la planification des examens universitaires
Terminé 2020 - 25
Overbet, des paris amicaux sur l’esport Overwatch
Terminé 2020 - 26
Domopack, un configurateur de maison connectée
Terminé 2020 - 27
GesPatApp, la gestion d’un centre de santé en Java
Actif 2019 - 28
DreamTeam, un journal de bord de projet terminal
Terminé 2019
- Reset Pack, réinstaller Windows en une commande
- tom-lefrere.fr, mon site personnel en quatre vies
- Esport Stats, une petite enquête data sur les scènes pros
- Answer, un question answering sur documents
- Animations Manim
- BestPick, un recommandateur de champions pour LoL
- Discord Recap, mon récap annuel reconstitué à ma sauce
- Divine Simulation, des IA qui jouent aux dieux dans WorldBox
- How Am I Lucky, une visualisation de la chance par les chiffres
- Home Assistant × Claude, la domotique augmentée par l’IA
- LoL Predict, une prédiction de matchs par ML
- Mathelearning, une plateforme d’apprentissage des maths
- Programme Maire, un test de compatibilité pour les municipales
- Visualisation de données YouTube
- Conscious, une application anti-gaspillage alimentaire
- Opinion Mining, une analyse de sentiments sur du texte
- GetSubscribedChannels, un export des chaînes YouTube
- Legermain, un site vitrine d’artisan
- Any%English, quelle part de YouTube je regarde en anglais ?
- DofusClassSelector, une analyse du ladder Dofus
- LunaSleep, la lune influence-t-elle ma qualité de sommeil ?
- Big4Craft, un site de tournoi Minecraft monté en urgence
- Université Populaire de l’Indre, une plateforme de cours
- ExamApp, la planification des examens universitaires
- Overbet, des paris amicaux sur l’esport Overwatch
- Domopack, un configurateur de maison connectée
- GesPatApp, la gestion d’un centre de santé en Java
- DreamTeam, un journal de bord de projet terminal
- data
- web
- python
- js
- java / php
- autre
Survole une étoile pour voir le titre · clique pour ouvrir · la vue suit ton curseur
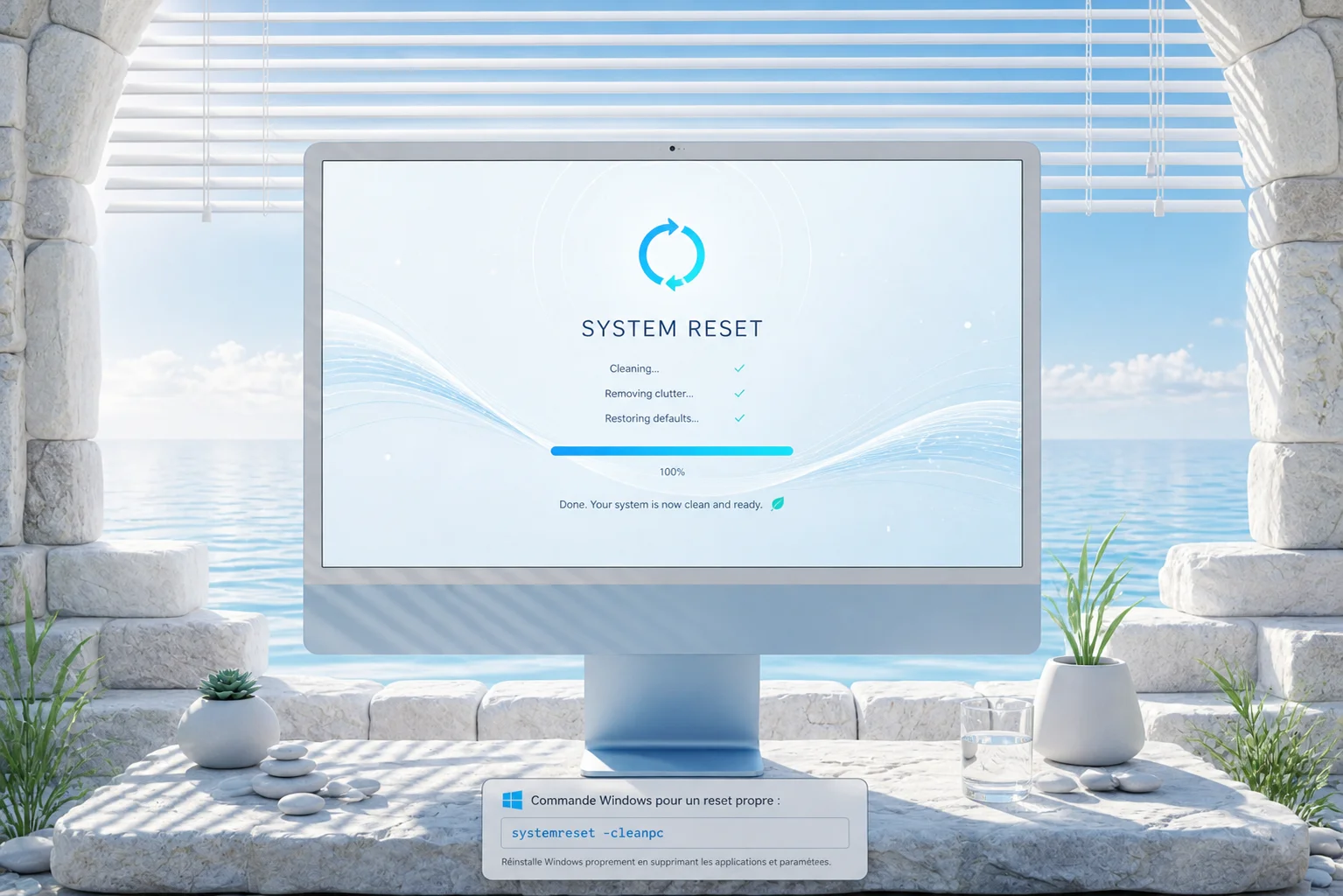
Reset Pack, réinstaller Windows en une commande
Pack PowerShell pour automatiser la réinstallation complète d'un PC Windows 11 après reset : apps, drivers, dev setup, tweaks, debloat, restauration des configs depuis OneDrive.
Pourquoi ?
Alors, pour le coup, je reset mes PC assez régulièrement, c’est quelque chose qui revient tous les 3 ou 4 mois chez moi. À force de refaire les mêmes gestes, j’ai fini par me construire une petite routine d’installation, et chaque génération de routine a évolué avec les outils du moment.
En 2021, c’était un Reset Pack basé sur Ketarin, une appli qui télécharge et installe automatiquement des packages d’install depuis une liste figée. À l’époque, c’était parfait : j’avais mes 7zip, Brave, Discord, Driver Booster, Everything, FileZilla, Office 365, PatchMyPC, PUTTY, VirtualBox, VLC, XAMPP qui s’installaient seuls pendant que je faisais autre chose. Les alternatives type Ninite ou PatchMyPC faisaient le même job, c’était surtout une question de goût.
Sauf qu’en 2026, le paysage a changé. winget est arrivé nativement dans Windows 11, ce qui rend Ketarin un peu obsolète. PowerShell 5.1 est toujours là, par défaut sur toutes les machines. Mes besoins, eux, se sont étoffés : il ne s’agit plus seulement d’installer une douzaine d’apps, mais aussi de remonter mon environnement dev (WSL2, gh, Git config, clés SSH), de restaurer mes configs (Claude Code, Claude Desktop, Obsidian, PowerToys, Windows Terminal), de virer les pubs et la télémétrie, de pin ma taskbar, et de réinstaller mes 30+ extensions VSCode.
D’où cette V2, complètement réécrite : Reset Pack, une suite de scripts PowerShell qui automatise tout ça en une seule commande après un Windows propre. Quelques minutes plus tard, j’ai retrouvé toutes mes apps, mes drivers, mes configs, mes raccourcis, mes tâches planifiées et même mes apps par défaut. La journée perdue à tout reconfigurer à la main, c’est fini.
Comment ça fonctionne
Le pack est découpé en 11 modules numérotés, chacun responsable d’une étape précise. Chaque module est idempotent, ce qui veut dire que je peux le relancer sans casser quoi que ce soit, et je peux n’en exécuter qu’un seul si besoin :
- 01-apps : install via
wingetde toutes mes apps depuis unapps.json(Brave, 7zip, Git, Obsidian, Signal, Steam, VLC, PowerToys, VSCode, Claude Desktop, Docker, Node, gh, etc.). - 02-drivers : NVCleanstall pour les Nvidia + SDIO pour le chipset/audio, lancés en mode silent.
- 03-dev-setup :
git config, WSL2 Ubuntu, long paths,gh auth loginavec génération de clé SSH. - 04-symlinks : restaure les configs depuis
OneDrive\Documents\08_Logiciels\Configs\via des symlinks (Git, Claude Code, Claude Desktop, Windsurf, Windows Terminal, PowerToys, Obsidian). - 05-vscode : réinstalle toutes les extensions depuis une liste figée.
- 06-tweaks : extensions de fichiers visibles, fichiers cachés, menu contextuel classique, widgets/Copilot off, télémétrie off, Win+V on.
- 07-defaults : Brave par défaut sur web/pdf/html, VLC pour le multimédia, via SetUserFTA (sinon Microsoft bloque la modification programmée des associations de fichiers).
- 08-debloat : Cortana et apps préinstallées dégagent, OneDrive reste.
- 09-games : symlinks Saved Games, My Games, et installs LoL/Overwatch/Dofus.
- 10-scheduled : tâche
winget upgrade --allhebdo et bascule auto dark/light (7h ↔ 20h). - 11-finalize : pin taskbar (Brave, Explorer, Terminal, Claude), hosts file pour le blocage de pubs, ouverture de la page Brave Sync.
À côté, un script backup-configs.ps1 qui tourne en amont du reset (ou périodiquement) et qui pousse toutes mes configs vers OneDrive, pour que la restauration ait des fichiers à pointer.
Et bien sûr, le meilleur ami de la productivité Windows est toujours là : PowerToys, que j’utilise tous les jours notamment pour le color picker et FancyZones. Il est installé par le module 01-apps et sa config est restaurée par les symlinks.
Mes contributions
Tout, du début à la fin. Architecture modulaire, scripts PowerShell, helpers communs (banner, log coloré, symlinks safe avec backup automatique de l’existant, retry, force-download OneDrive Files On-Demand), gestion des modes interactif et -Auto, élévation admin automatique, normalisation des arguments comma-separés (parce que PowerShell 5.1 fait ça mal). J’ai aussi prévu deux variantes selon la machine cible (Codect et EXODIUS), ce qui me permet de garder un set d’apps légèrement différent par poste.
Ce que j’ai retenu
L’idempotence, c’est la clé. Un script qu’on n’ose pas relancer parce qu’on ne sait pas ce qui va se passer, c’est un script qu’on ne maintient pas. Là, je peux relancer n’importe quel module dix fois de suite, ça ne change rien si l’état est déjà bon. Du coup, je teste sans crainte, et c’est ce qui m’a permis d’itérer rapidement.
PowerShell 5.1 a des pièges, vraiment. Le passage de paramètres comma-separés via -File qui ne split pas vers [string[]], les permissions admin qui se perdent au relancement, les symlinks qui peuvent être verrouillés par PowerToys ou Claude Desktop le temps qu’on les remplace. Bref, il a fallu prévoir des retries un peu partout, parce qu’on est sur du Windows et que rien n’est jamais garanti.
Centraliser les configs sur OneDrive, c’est gagné. Avant, j’avais des bouts de configs un peu partout, et à chaque reset je perdais des trucs. Maintenant, tout est dans OneDrive\Documents\08_Logiciels\Configs\, versionné implicitement par OneDrive, et les symlinks font le reste. Si je modifie une config sur un poste, elle se propage toute seule.
Les apps par défaut sur Windows 11, c’est verrouillé. Microsoft empêche la modification programmée des associations de fichiers, du coup il faut passer par SetUserFTA, qui exploite un hash interne pour faire passer les modifs. Dommage que ça en soit là, mais le contournement marche très bien.
Contexte
Projet personnel, V2 d’une routine que j’entretiens depuis 2021. La perspective de repasser une journée entière à réinstaller, configurer, re-pin la taskbar, et re-cocher cinquante-douze cases dans les paramètres Windows à chaque reset, c’est ce qui m’a poussé à pousser le truc bien plus loin que la version Ketarin originale. Le pack a été développé en binôme avec Claude Code, ce qui m’a permis de cranker à fond sur l’écriture des modules et de me concentrer sur les cas particuliers (gestion des erreurs, retries, comportements de winget, etc.).
Bonnes installations, et surtout bonne routine.
Technologies utilisées
- PowerShell 5.1+
- winget (Windows Package Manager)
- WSL2 / Ubuntu
- SetUserFTA (associations de fichiers)
- NVCleanstall + SDIO (drivers)
- gh CLI (GitHub auth)
- OneDrive (storage des configs)
tom-lefrere.fr, mon site personnel en quatre vies
Historique des quatre versions de mon site, de PHP pur en 2019 à Astro + Sveltia CMS + MCP aujourd'hui. Un terrain d'expérimentation permanent.
Le projet
Depuis 2019, je maintiens mon site personnel pour exposer mes projets et expérimenter de nouvelles technos web. Il a connu quatre versions successives, ce qui fait qu’il reflète assez bien mon évolution en tant que développeur, pour le coup. Chaque refonte a été l’occasion de creuser un nouveau stack, de tester ce qui marche vraiment, et de jeter ce qui ne tient pas la durée.
Version 1, 2019
Première version très simple, réalisée en PHP pur avec quelques animations JavaScript. Fonctionnalités minimalistes, évidemment, mais c’était une première expérience de mise en production, ce qui compte beaucoup quand on débute.
Version 2, 2020
Refonte complète en Vue.js pour découvrir ce framework. Intégration de librairies comme GSAP et jQuery pour des animations plus soignées. C’était typiquement la version où je voulais prouver que je savais faire, notamment sur l’aspect visuel.
Version 3, 2021-2026
Migration vers WordPress pour simplifier la maintenance et me concentrer sur le contenu plutôt que sur l’infrastructure. Beaucoup moins de temps à maintenir, beaucoup plus à écrire, ce qui était la bonne balance à l’époque. Mais avec le temps, le combo WordPress + plugins + thème custom est devenu lourd, lent au chargement, et son expérience éditoriale ne me convenait plus.
Version 4, 2026 · actuelle
Refonte totale en Astro 5 (SSG) avec Sveltia CMS, serveur MCP et deploy O2switch via GitHub Actions. Cette version a une ambition différente des précédentes : devenir un site fiable, rapide, mesurable, bilingue et traçable, sans sacrifier le côté un peu vivant que j’aime bien.
Les principes qui ont guidé la refonte :
- Tout en statique pour zéro compute serveur à l’exécution, un TTFB quasi instantané, et une charge infra nulle côté hébergeur.
- Charte Deep Space : fond bleu nuit
#0a0f1f, accent jaune#fdf854, typo Space Grotesk + JetBrains Mono. Ambiance cohérente de bout en bout. - Bilingue natif (FR / EN) avec détection automatique, URLs
/et/en/,hreflangself-referencing, et 27 projets + 2 pages légales traduits ligne par ligne. - Contenu versionné en git dans
src/content/projects/*.mdxavec schéma Zod validé, plutôt que dans une base de données opaque. - Audité en continu : chaque push CI rejoue des audits éco et accessibilité, résultats affichés dans une app dédiée côté site (Impact 🌱).
Ce que ça donne concrètement
- Tom OS, une section CV qui mime un bureau macOS avec une rangée d’apps cliquables (Expérience, Formation, Compétences, Terminal, Playground SHAP, Iris UMAP, Booster Pokémon-like, Snake, Impact). Métaphore un peu joueuse qui me ressemble mieux qu’un simple PDF à télécharger.
- Command palette (⌘K ou Ctrl+K) pour sauter à n’importe quel projet, ouvrir une app, switcher de langue, basculer en mode blueprint, couper l’audio. Fuzzy-search, multi-groupes, deep-link via
?q=. - Portfolio en 3 vues : slider défilant, liste éditoriale, et constellation SVG où chaque projet est une étoile positionnée dans un plan année × catégorie. Modale plein écran qui s’ouvre sans quitter la page, deep-link
#p-slug, bouton fermer qui tourne au hover. - Filtres multi-tags : search input + pills toggle multi-select + top-N avec “voir plus”. 40 tags distincts extraits automatiquement depuis le contenu des articles via un dictionnaire de regex.
- Serveur MCP qui expose le contenu du site comme outils pour Claude Desktop ou Claude Code. 12 outils (list/get/create/update/delete projects, pages, medias, git_status, commit_and_push), validation Zod, sandbox
SITE_ROOT, tests d’intégration vianode --test. - Impact app avec les scores éco (96/100 via Sustainable Web Design v4), a11y (99/100 via heuristiques WCAG 2.2), tests (15/15 passing), perf runtime. Chaque jauge a une méthodo dépliable qui explique le calcul, pour que ce soit auditable et pas juste décoratif.
- Éditoriaux riches : PDF buttons stylés, galeries responsive avec hover zoom, composant
<VideoEmbed>pour les démos, tout depuis MDX.
Mes contributions
Tout, du début à la fin. Conception, architecture, intégration, outils d’audit, déploiement, doc. Le repo contient en plus :
- Scripts automatisés :
eco-audit.mjs(impact carbone par visite),a11y-audit.mjs(63 pages scannées),extract-tags.mjs(auto-tagging par regex),optimize-images.mjs(conversion PNG → WebP via sharp),generate-audit-report.mjs(serialise les scores en JSON consommé par l’app Impact),import-wp.mjs(migration WordPress initiale). - Tests CI : 6 tests de structure build, 9 tests MCP en stdio JSON-RPC, toujours verts avant merge.
- GitHub Actions : jobs check + build + test + audit + mcp-test en parallèle, deploy O2switch en FTPS après chaque push sur
main. - Cloudflare Worker pour l’OAuth GitHub (api.netlify.com refuse les sites hors-Netlify depuis 2026). Gratuit, 5 min à déployer, sécurisé côté secrets.
- SEO 93/100 : sitemap i18n, robots avec
max-image-preview:large, hreflang self-ref, schemas Person + WebSite + BlogPosting + BreadcrumbList (éligibles rich snippets Google), OG images SVG 1200×630 générées à la volée par projet.
Ce que j’ai retenu de cette V4
Le SSG, c’est du vrai confort. Une fois que j’ai migré sur Astro, la vitesse de dev a explosé. Hot-reload instantané, pas de base de données à babysit, tout le contenu en git avec du diff propre. Pour un portfolio perso, c’est le bon niveau d’abstraction, vraiment.
Les LLM changent la donne côté éditorial. L’idée d’un serveur MCP sur mon propre contenu, c’était un peu expérimental au départ. Aujourd’hui je peux demander à Claude “liste mes projets par date, crée un brouillon foo, commit et push”, et c’est exécuté. Ça enlève énormément de friction sur les petites MAJ, et ça ouvre la voie à des usages plus ambitieux (auto-tagging, suggestions de titres, cross-linking, etc.).
Mesurer, c’est déjà corriger. L’app Impact affiche les scores en live sur le site. Rendre les chiffres visibles, ça force à ne pas les laisser glisser. Quand l’éco descend sous 90, je le vois à chaque nouvelle feature que je push, du coup j’arbitre autrement.
L’accessibilité a un coût zéro. 99/100 sur l’audit a11y, ce n’est pas un objectif en soi mais le résultat naturel de bonnes pratiques (landmarks sémantiques, alt systématique, skip link, contraste correct). Le seul “low” qui reste, c’est l’absence de skip link sur la page /admin/ du CMS, qui est de toute façon désindexée.
Bilingue, c’est doublement du boulot. 27 projets × 2 langues = 54 articles à maintenir. Sans l’infra multilang solide (schéma lang, filtre getCollection, normalisation des slugs en/xxx → xxx), ça devient vite un cauchemar. Je ne regrette pas, mais il faut avoir conscience de la charge.
Contexte
Projet personnel, en continu depuis 2019. La V4 a été développée en une semaine intensive avec Claude Code, code entièrement écrit et audité en binôme avec lui.
Technologies utilisées
| Couche | V4 (2026) |
|---|---|
| Framework | Astro 5 (SSG, content collections, i18n) |
| Langage | TypeScript |
| Styling | CSS custom properties + Tailwind ponctuel |
| Content | MDX + gray-matter + Zod validation |
| CMS | Sveltia CMS (fork moderne de Decap) |
| Auth CMS | Cloudflare Worker OAuth (sveltia-cms-auth) |
| MCP | @modelcontextprotocol/sdk sur stdio JSON-RPC |
| Image | sharp (PNG → WebP, -97%) |
| Host | O2switch (cPanel Apache) |
| Deploy | GitHub Actions FTPS |
| Tests | node —test (natif, zéro dépendance) |
Précédentes vies pour l’historique :
- V1 : PHP / JavaScript (2019)
- V2 : Vue.js / GSAP / jQuery (2020)
- V3 : WordPress (2021-2026)
- V4 : Astro + Sveltia CMS + MCP (avril 2026)
Esport Stats, une petite enquête data sur les scènes pros
Un projet perso parti d’une question un peu bête (qui sont les plus jeunes ? qui sont les plus vieux ?) et qui a fini en petit rapport éditorial avec du Python, du Plotly, un PDF imprimable, et quelques pièges méthodologiques en chemin. Alors, pour le coup, voilà comment j&
Un projet data fait sur un week-end, parti d’une question un peu bête sur l’âge des joueurs pros, et qui a fini en rapport éditorial de 15 pages. C’est un de ces trucs qu’on commence le samedi soir en se disant « bon, vite fait », et évidemment pas du tout.
Alors, pour le coup, tout est parti d’une curiosité un soir. Je me demandais, c’est quelque chose qu’on entend souvent sans vérifier, si c’était vrai que les scènes FPS cassaient les carrières tôt, et que Dota 2 était peuplé de vétérans qui traînent depuis dix ans. Je voulais une réponse chiffrée, propre, et tant qu’à faire, pas trop moche à regarder. Du coup, j’ai sorti un notebook, je me suis dit que je réglais ça en deux heures, et évidemment, ça a pris un peu plus.
Le point de départ
L’idée initiale, c’était de scraper Liquipedia, sortir un bar chart, on n’en parle plus. J’ai vite changé d’avis en tombant sur PandaScore, qui est une API e-sport plutôt bien faite, notamment pour qui veut jouer avec des données structurées sans se retrouver à parser du HTML instable. 1000 requêtes par heure sur le plan gratuit, des endpoints propres pour les joueurs, les équipes, les tournois. C’est largement suffisant pour ce genre d’exercice.
J’ai retenu six jeux, c’est-à-dire League of Legends, Counter-Strike, Dota 2, Valorant, Rainbow 6 Siege et Overwatch. L’idée étant de ne regarder que le tier S, donc l’élite (LCK, LEC, VCT Masters, BLAST Major, The International, ce genre de choses), et uniquement les joueurs actifs. Pas de semi-pro, pas de joueurs retirés qui traînent encore dans la base. C’est un portrait de 2026, pas un recensement.
Les premières embûches
Les premières heures ont été une petite traversée de pièges classiques, c’est-à-dire ce genre de trucs qui te font douter de l’API avant que tu réalises que tu t’étais juste trompu toi-même.
- Le champ
birthdayqui semblait absent des réponses, alors qu’en fait PandaScore omet simplement les champs null. Faker a bien sa date de naissance, un joueur de tier 3 anonyme ne l’a pas, et c’est normal. J’ai perdu une heure avant de comprendre ça. - Les slugs de l’API qui ne sont pas ceux des jeux. Dans la liste, c’est
cs-go, mais dans l’URL il faut écrire/csgo/. Pareil pourdota-2qui devient/dota2/. C’est un petit détail, mais ça coûte trois 404 avant de tilter. - Pas de champ
tiersur les ligues, mais oui sur les tournois. Ce qui fait que le filtre utile, c’estfilter[tier]=sappliqué aux tournois, pas aux ligues. Une fois qu’on a compris ça, ça déroule. - Le rate limit évidemment, qui tombe vite quand on explore en tâtonnant. J’ai tapé les 1000 calls en une session, ce qui a été l’occasion d’ajouter un cache disque JSON sur chaque requête. Résultat, les re-runs sont instantanés, et c’est clairement cinq minutes de code qui m’ont fait gagner beaucoup de temps après.
Le pipeline
L’architecture finale tient en trois scripts Python, et l’idée étant de pouvoir les enchaîner sans se poser de questions. Le premier, etl.py, interroge PandaScore et sort quatre CSV. Il y a players_top.csv pour les joueurs actifs uniques, tournaments.csv pour les métadonnées des tournois (avec le vainqueur), participants.csv pour le lien tournoi-équipe, et surtout rosters.csv, qui est la vraie clé de voûte du projet parce qu’il contient les rosters historiques, donc qui a joué quoi quand. J’y reviens plus bas, c’est ce fichier qui a permis de corriger l’erreur méthodo dont je parle après.
Le deuxième, viz.py, transforme les CSV en un rapport HTML éditorial. C’est là que j’ai essayé de sortir un peu du côté « dashboard utilitaire » pour aller vers quelque chose de plus lisible. Typographie sérif pour les titres (Cormorant Garamond), sans-serif pour le corps (Inter), une palette crème et terracotta, des captions en italique. Plotly thémé pour que les charts soient cohérents avec le reste. Onze charts au total, avec une table DataTables triable, et des insights auto-générés en tête de rapport (genre « Dota 2 est la scène la plus mature, 2.5 ans de plus qu’Overwatch »).
Le troisième, pdf.py, utilise Playwright pour charger le HTML dans un Chromium headless, attendre la fin du rendu Plotly, appliquer le CSS @media print, et sortir un PDF de 15 pages. Ce n’est pas la partie la plus triviale, j’y reviens aussi.
Le piege méthodo à ne pas laisser passer
C’est la partie dont je suis le plus content d’avoir vu passer, parce que franchement, elle aurait pu passer inaperçue. Dans la première version du rapport, il y avait un chart d’évolution de l’âge médian année par année, très propre visuellement. Sauf qu’il était linéaire par construction, c’est-à-dire que je prenais la cohorte actuelle et je reculais dans le temps en faisant année - date_de_naissance. Chaque joueur vieillissant d’exactement un an par an, la médiane bougeait mécaniquement d’un an. Zéro information réelle, mais évidemment, ça a l’air d’en dire beaucoup.
Ce qui m’a sauvé, c’est une question du « client » (moi-même en l’occurrence, en relecture à froid) qui m’a dit que ça avait l’air un peu trop beau. J’ai regardé à nouveau, et oui, c’était un artefact mathématique pur. Réflexe important, du coup, qu’on n’a pas toujours : se demander si un chart qu’on trouve parlant pourrait être construit autrement qu’en reflétant une vérité.
La correction est venue d’une petite découverte côté API. L’endpoint /tournaments/{id}/teams ne renvoie pas les rosters actuels des équipes qui ont joué, il renvoie les rosters au moment du tournoi, ce qui change tout. En sauvant une table rosters.csv avec une ligne par (tournoi, équipe, joueur), on peut calculer pour chaque année qui a vraiment joué et quel était son âge à ce moment-là. Chaque année a du coup sa propre cohorte, les nouveaux entrent, les anciens sortent, et le chart devient réellement informatif.
Résultat, Dota 2 a gagné environ 2 ans de médiane depuis 2020, R6 Siege en a pris 3, Counter-Strike est stable, Valorant aussi. C’est le genre de résultat qui correspond au ressenti de la communauté, ce qui est rassurant après un gros bug méthodo comme celui-là. Même si, évidemment, ça reste à prendre avec une certaine prudence : on ne couvre pas toutes les années à la même profondeur, notamment sur les très vieux tournois.
Ce que le rapport révèle
Quelques résultats que je trouve intéressants, même si je précise évidemment qu’il s’agit d’un snapshot ponctuel et pas d’une vérité absolue.
- Dota 2 est la scène la plus mature, avec 26.8 ans de moyenne, et Overwatch la plus jeune, à 24.3 ans. 2.5 ans d’écart, c’est considérable à l’échelle d’une carrière pro, et ça recoupe notamment la durée de vie des jeux dans l’écosystème (Dota 2 tourne depuis 2013, Overwatch a redémarré plus récemment avec OW2).
- La scène la plus internationale, au sens de l’indice de Shannon, est Counter-Strike (0.82). La plus homogène, c’est Overwatch (0.63), très dominée par la Corée et les États-Unis. Ce qui n’est pas surprenant pour qui suit un peu la scène, mais c’est toujours pas mal de l’avoir chiffré.
- 62 % des joueurs de Counter-Strike tier S viennent de la région EMEA. C’est la concentration régionale record du dataset.
- Sur League of Legends, les rosters vainqueurs sont en moyenne 0.4 an plus jeunes que la scène. L’écart est léger, mais mesurable. C’est pas de quoi faire une grande théorie, mais c’est un petit signal.
- Le doyen du dataset c’est TaZ (39 ans, Counter-Strike), le benjamin c’est TaiLung (15 ans, Dota 2). Fourchette de 24 ans dans le même écosystème pro, voilà.
Les visualisations
Le rapport est structuré en cinq parties plus une annexe. La première partie sur l’âge des pros, avec un bar chart des moyennes, un ridgeline plot des distributions (plus éditorial qu’un violin plot classique, c’est un détail mais ça change la lecture), et une table des doyens et benjamins. La deuxième partie sur l’évolution des scènes, avec les cohortes de naissance empilées et la fameuse courbe temporelle corrigée.
La troisième partie est la plus dense, c’est la géographie. Une carte monde choroplèthe, un top 15 des pays représentés, les parts régionales par jeu (EMEA, Americas, Asia, Oceania), des small multiples pour le top 6 des pays par discipline, un Sankey des migrations (joueur né dans un pays, signé dans une équipe d’un autre pays), l’indice de diversité de Shannon, et des mini-cartes indépendantes par jeu. C’est peut-être un peu trop, mais c’était difficile de choisir.
La quatrième partie est sur la performance. Âge moyen des rosters vainqueurs versus l’ensemble, et un top 3 des écuries par discipline, normalisé par le nombre de tournois du jeu. Normaliser, c’est une évidence quand on y pense, mais au départ j’avais mis un top brut, ce qui faisait que Counter-Strike écrasait tout simplement parce qu’il y a trois fois plus de tournois que sur LoL. Pour le coup, c’est typiquement le genre de biais qu’on repère en regardant le chart et en se disant « attends, ça raconte pas l’histoire que je veux ».
La cinquième partie, c’est une tuile par jeu avec les chiffres-clés et la composition des rôles. Et en annexe, une petite comparaison avec le sport traditionnel : NBA 26.4, Premier League 27.1, NFL 26.6, ATP 27.3, esport 25.4. Les rosters e-sport d’élite sont bien plus jeunes que la plupart des sports pros, mais l’écart est moins spectaculaire qu’on pourrait le croire, notamment si on isole des scènes comme Dota 2 qui sont au niveau de la Premier League.
Le rendu PDF
Sortir un PDF propre depuis du Plotly, c’est pas du tout trivial, c’est quelque chose que je n’avais pas mesuré au départ. Les charts sont des SVG interactifs, dimensionnés au moment du premier rendu dans le navigateur. Du coup, si on passe simplement en print, la mise en page casse, parce que le chart garde la largeur d’origine (typiquement 1200px de viewport HTML) alors que la page A4 fait 794px.
La recette qui marche avec Playwright, pour le coup, c’est de charger le HTML, d’attendre que tous les .js-plotly-plot aient leur .main-svg, puis d’appeler page.emulate_media("print") pour activer le CSS print, ensuite de réduire le viewport à la largeur A4 (794px), et là, de forcer un Plotly.Plots.resize() sur chaque chart pour qu’il se recalcule. On attend une seconde et demie que la relayout se stabilise, puis page.pdf(). C’est un peu bricolé, mais ça donne un résultat propre.
Côté CSS, le print a ses propres règles : empiler les deux-colonnes en une seule (les charts prennent toute la largeur), masquer la chrome DataTables qui n’a aucun sens hors ligne, imposer des sauts de page propres entre les grandes parties, réduire les hauteurs pour qu’un chart tienne avec sa légende et sa note méthodologique sur une seule page. Ce qui fait beaucoup de petits ajustements avant d’obtenir un PDF qu’on a envie d’ouvrir jusqu’au bout.
Ce qui reste pour la V2
Deux pistes demandent plus de temps de calcul API et partiront en V2. D’abord la longévité de carrière, qui nécessite d’interroger /players/{id}/tournaments pour chaque joueur. On parle de 2600 requêtes, soit environ trois heures de fetch en respectant le rate limit. L’hypothèse serait que les carrières sont très courtes sur les FPS, et bien plus longues sur les MOBA. Ce serait intéressant à chiffrer.
Ensuite la rotation des rosters, c’est-à-dire le pourcentage de joueurs qui changent d’équipe d’une année sur l’autre. C’est une métrique souvent commentée par la communauté, notamment autour des transferts d’intersaison, mais assez rarement chiffrée proprement. Ça devrait être faisable sans trop de calls supplémentaires, vu qu’on a déjà le rosters.csv.
La stack technique
Rien de très exotique pour le coup. Python 3.13 avec requests, pandas, numpy, pycountry, python-dotenv. Plotly pour tous les charts, avec un thème simple_white personnalisé. DataTables.js pour la table interactive (c’est léger et ça fait le boulot). Playwright plus Chromium headless pour le rendu PDF fidèle. Et PandaScore comme source unique de données.
Ce que ce projet m’a appris
Trois trucs m’ont marqué, plus ou moins liés au sujet même.
Le premier, c’est qu’un chart qui paraît clean peut cacher un biais méthodologique majeur. Le réflexe de se demander « est-ce que cette ligne pourrait être construite autrement qu’en reflétant une vérité ? », c’est quelque chose qui vaut son pesant d’or. Mon chart linéaire aurait pu passer pour un insight, alors que c’était un pur artefact. Du coup, je m’efforce de plus en plus de faire ce genre de relecture à froid, idealement le lendemain, parce qu’à chaud on est un peu trop fier de son résultat pour le critiquer honnêtement.
Le deuxième, c’est la différence entre un dashboard utilitaire et un rapport éditorial. Ce qui fait que ça tient à très peu de choses en fait : une typo sérif pour les titres, une palette muted, des captions en italique, des sauts de page soignés. Mais ça change la perception du lecteur du tout au tout. C’est un détail de forme qui déplace la catégorie mentale dans laquelle le document est rangé.
Le troisième, c’est plus bateau mais je le note quand même : il y a toujours un rate limit quelque part. Ajouter un cache disque dès le début de l’exploration, c’est cinq minutes de code qui en font gagner cinquante. Je le sais, j’essaie de le faire, et j’oublie quand même une fois sur deux.
Le rapport éditorial complet (15 pages)Projet bouclé en une soirée et quelques heures en plus. Avec l’API payante de PandaScore on ouvrirait d’autres horizons (plus d’années d’historique, plus de calls pour la longévité), mais même en gratuit, c’est une base solide pour qui veut jouer avec les données e-sport. Et honnêtement, si vous cherchez une idée de projet data à la fois riche, faisable, et suffisamment originale pour tenir dans un CV, c’est typiquement le genre de sujet que je recommanderais. Voilà.
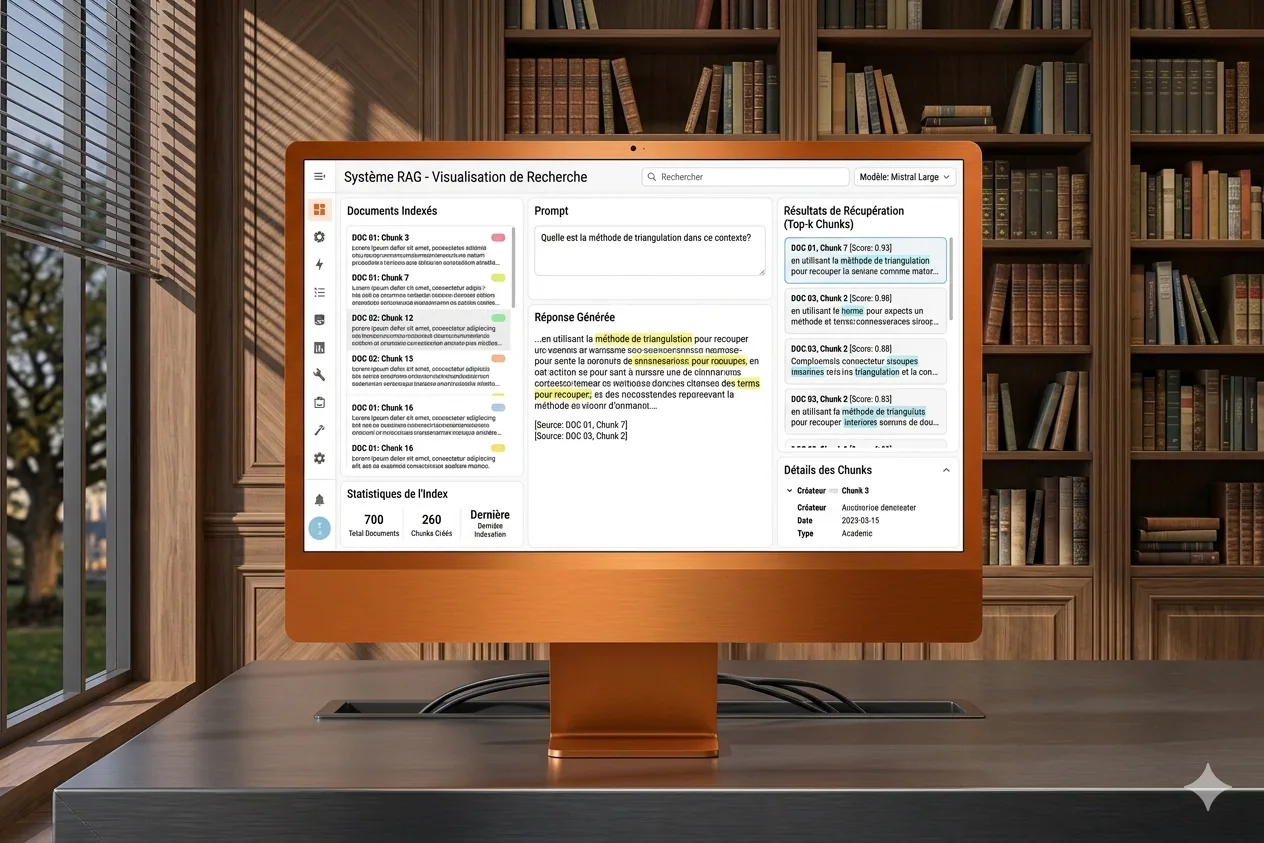
Answer, un question answering sur documents
Fork enrichi du projet Answer de Dataiku pour la visualisation RAG, avec des fonctionnalités supplémentaires demandées par les clients.
Le projet
Answer, pour le coup, c’est un fork du projet Answer de Dataiku, qui propose une visualisation de RAG. C’est une webapp clé en main, mais au quotidien il manquait pas mal de fonctionnalités, et mes clients demandaient régulièrement des améliorations. Du coup, j’ai décidé de prendre les choses en main en créant ce fork pour y ajouter ce qui manquait. C’est typiquement le genre de cas où on pourrait attendre un release officielle, mais bon, en consulting, ça ne marche pas trop comme ça.
Mes contributions
Fork et enrichissement de l’application originale : ajout de fonctionnalités demandées par les clients, amélioration de la visualisation RAG, corrections et adaptations pour les cas d’usage réels rencontrés en entreprise. L’idée étant de garder une version utilisable tout de suite, sans attendre que l’upstream bouge.
Ce que j’ai retenu
Reprendre un projet open source existant et l’adapter aux besoins réels du terrain, c’est un exercice très formateur. Ça m’a notamment permis de comprendre en profondeur le fonctionnement du RAG, et les attentes concrètes des utilisateurs en entreprise, qui sont souvent assez loin des cas de démo qu’on voit dans les présentations.
Contexte
Projet professionnel. En tant que consultant, je constatais des manques récurrents dans l’outil de visualisation RAG de Dataiku. Plutôt que d’attendre, du coup, j’ai forké le projet pour y répondre, quitte à devoir re-synchroniser plus tard si l’upstream intégrait les mêmes idées.
Technologies utilisées
-
Python
-
Node.js
-
Gulp (build system)
-
Playwright (tests)
-
OpenAPI
-
Dataiku
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
Animations Manim
Génération d’animations pédagogiques avec Manim et LLM pour expliquer visuellement des concepts techniques comme le RAG.
Le projet
C’est quelque chose qui me tient à cœur : j’aime beaucoup expliquer les choses visuellement, mais créer des animations prend énormément de temps. En découvrant Manim (la librairie derrière les vidéos 3Blue1Brown), j’ai vu une opportunité : utiliser un LLM pour générer rapidement des représentations visuelles cohérentes de concepts techniques. Ici, c’était le RAG, mais évidemment, le principe s’applique à n’importe quel sujet technique, notamment ceux qu’on explique mal à l’oral.
Mes contributions
Développement de scripts Manim pilotés par LLM pour générer des animations techniques. Création de deux variantes d’animation RAG (continue et fluide) avec des approches visuelles différentes. Optimisation du workflow LLM vers Manim vers GIF, pour gagner un peu de temps sur les itérations.
Ce que j’ai retenu
Manim, pour le coup, c’est un outil incroyable pour la vulgarisation technique. Coupler un LLM avec un outil de génération d’animations ouvre des possibilités énormes pour produire du contenu pédagogique rapidement. Le principal défi, c’est quand même d’obtenir des résultats visuellement propres du premier coup, ce qui n’arrive pas toujours, et il faut souvent re-prompter un peu.
Contexte
Projet personnel, né de l’envie de vulgariser des concepts IA complexes (ici le RAG) de manière visuelle et élégante, sans y passer des jours. L’idée étant vraiment d’avoir une chaine de production rapide pour les anim.
Exemple d’animation faite en oneshot
Technologies utilisées
-
Python
-
Manim
-
LLM (génération assistée)
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
BestPick, un recommandateur de champions pour LoL
Interface rapide pour savoir quel champion jouer contre mon adversaire à League of Legends, basée sur mes picks et les données de matchup.
Le projet
Alors, pour le coup, j’ai toujours été assez mauvais à League of Legends, et je maîtrise un pool de champions assez restreint. BestPick, c’est une interface simple où je présélectionne les champions que je sais jouer, et quand je connais mon adversaire, l’outil me dit lequel de mes picks est le plus pertinent contre lui. C’est un petit projet rapide, mais qui marche plutôt bien, notamment parce que le besoin derrière était très concret.
Mes contributions
Développement complet : scripts Python pour la collecte de données de matchups et winrates, base de données SQL pour stocker les statistiques, et interface web PHP pour la consultation rapide en jeu. L’idée étant d’avoir quelque chose d’accessible en deux clics, parce que la fenêtre de champ select est courte.
Ce que j’ai retenu
Même un petit projet utilitaire peut être très satisfaisant quand il résout un vrai problème, pour le coup. Combiner Python côté data et PHP côté web dans une même archi, ça fonctionne bien pour ce type de cas, notamment quand on veut séparer le scraping et l’affichage. Et les données de matchup en jeu vidéo, c’est un terrain de jeu passionnant pour l’analyse de données, même si évidemment, elles ne remplacent pas la pratique.
Contexte
Projet personnel, né du besoin d’optimiser ma phase de sélection de champions en ranked quand on n’a pas un pool très large. Typiquement le genre de truc qu’on se construit pour gagner deux minutes et un peu de winrate au passage.
Technologies utilisées
-
Python
-
PHP
-
MySQL / SQL
-
HTML / CSS / JavaScript
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
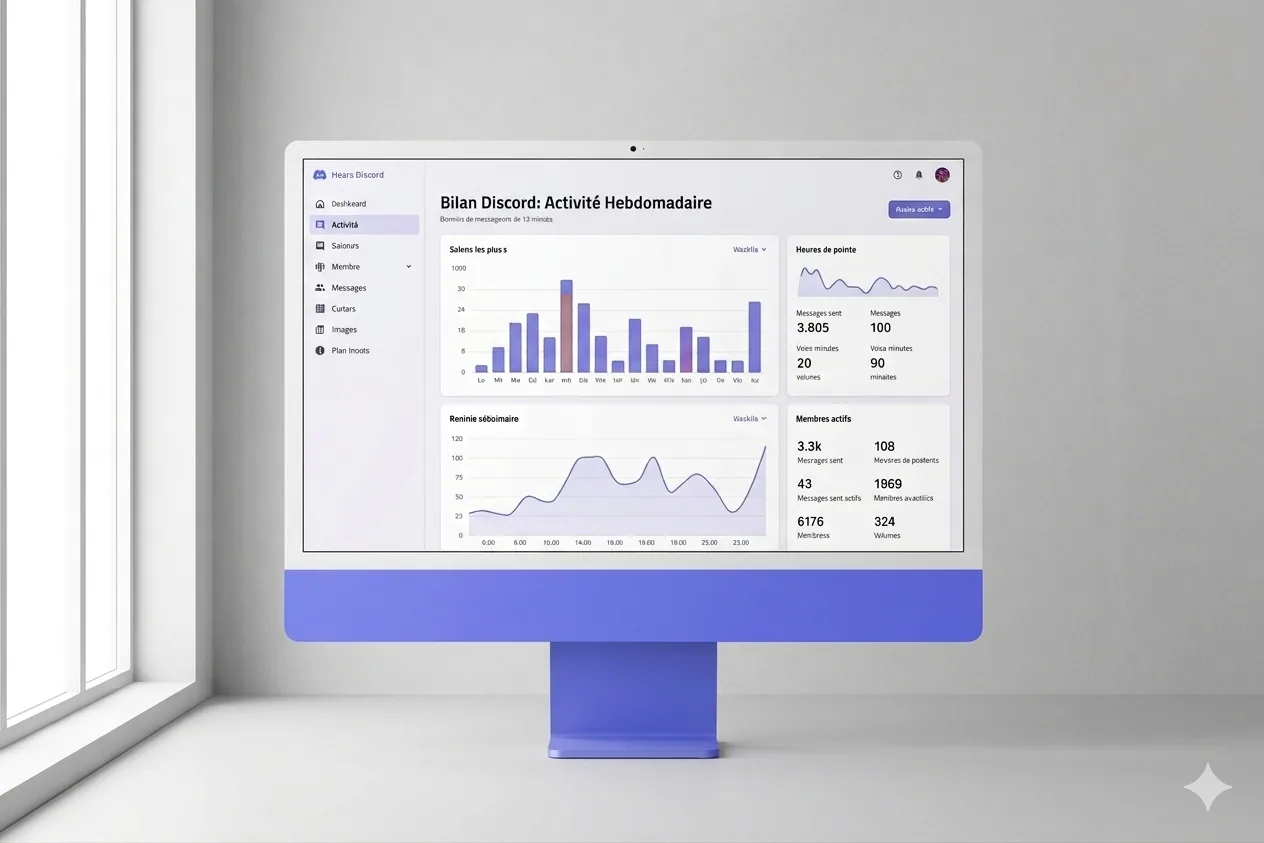
Discord Recap, mon récap annuel reconstitué à ma sauce
Mon propre récap Discord, bien plus complet que l’original, avec des visualisations Recharts et export PDF, en React 19 et TypeScript.
Le projet
En faisant mon récap de l’année 2025, je me suis rendu compte que je ne pouvais pas accéder à celui de Discord, parce que je ne partage pas mes données avec eux, et de toute façon, leur récap était assez léger. Du coup, je me suis dit : si cette donnée existe quelque part, il faut que je la récupère et que je l’utilise. J’ai donc monté mon propre système de récap, avec plein d’indicateurs supplémentaires : temps de jeu, nombre de sessions, et bien plus. Le résultat est beaucoup plus intéressant que ce que Discord propose, pour le coup.
Mes contributions
Développement complet de l’application web : interface React avec TypeScript, visualisations interactives avec Recharts, génération de rapports PDF avec jsPDF, et navigation multi-pages avec React Router. L’idée étant de pouvoir exporter un document propre et partageable, pas juste un dashboard éphémère.
Ce que j’ai retenu
Récupérer ses propres données et en faire quelque chose de mieux que la plateforme d’origine, c’est quelque chose de très satisfaisant. React 19 avec TypeScript, pour le coup, offre une expérience de développement très fluide, notamment sur le typage des props et des hooks. Et Recharts combiné à jsPDF permet de créer des rapports visuels exportés proprement, même s’il y a évidemment quelques petites contorsions sur la mise en page PDF.
Contexte
Projet personnel, né de la frustration de ne pas avoir de récap Discord digne de ce nom. Inspiré par le Spotify Wrapped, appliqué à ma communauté Discord. C’est typiquement le genre de truc qui part d’un manque et qui finit en petit outil perso utile.
Voici un extrait du résultat en PDF
Récap Discord 2025, version complèteTechnologies utilisées
-
React 19 / React Router DOM
-
TypeScript
-
Vite 7
-
Tailwind CSS 4
-
Recharts
-
jsPDF
-
ESLint
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
Divine Simulation, des IA qui jouent aux dieux dans WorldBox
Quatre agents IA incarnent des dieux aux personnalités contrastées dans WorldBox, négocient au conseil, complotent, et tissent leurs religions sur 1000 ans de simulation.
Le projet
Alors, pour le coup, tout est parti d’une session WorldBox. Pour ceux qui ne connaissent pas, c’est un god game où on observe des civilisations naître, se battre, fonder des religions, et se faire rouler dessus par une météorite qu’on a déclenchée deux minutes avant. Et à un moment, je me suis dit : et si les dieux du jeu étaient de vraies IA, avec des personnalités, des stratégies, et des rancunes les unes contre les autres ?
Du coup, j’ai monté un système où quatre agents IA (Claude, via Anthropic) incarnent chacun un dieu, Ares le guerrier, Gaia la bienveillante, Loki le trickster, Athena la stratège. Chaque dieu pilote plusieurs religions dans le jeu, bénit ses fidèles, maudit ses ennemis, déclenche des catastrophes, négocie au conseil des dieux, et évidemment, complote contre les autres dès qu’il peut.
L’objectif final, c’est de filmer une simulation de 1000 ans et d’en faire une vidéo YouTube, pour voir quel type de personnalité divine l’emporte quand on les lâche longtemps.
L’architecture tient en trois briques :
- Un mod C# qui expose l’état du jeu via une API HTTP (42 outils)
- Un orchestrateur Node.js qui fait réfléchir les dieux via Claude et exécute leurs actions
- Un dashboard React pour tout visualiser en temps réel et rejouer les parties
Mes contributions
Le mod WorldBox (C# / .NET 4.8)
Développement complet de WorldBoxMCP, un mod qui expose le jeu via un serveur HTTP JSON-RPC 2.0. Concrètement, ça donne :
- 42 outils MCP. Lecture de l’état du monde (royaumes, créatures, religions avec leur fondateur, leurs traits, leurs fidèles notables), actions divines (bénédictions, malédictions, catastrophes, diplomatie, terraforming), contrôle temporel (pause, vitesse), et intégration religion (ajout de traits comme
summon_lightningounecromancy, conversion de fidèles, changement de couleur des bannières). - Gestion du threading Unity via un
MainThreadDispatchercustom. Les appels HTTP arrivent sur un thread background, mais les opérations de jeu doivent tourner sur le thread principal, sinon Unity hurle et le jeu crashe. C’est un classique, mais il fallait le faire proprement. - Fix du pathfinding. La création d’îles artificielles faisait crasher le jeu parce que les régions de navigation n’étaient pas recalculées après terraforming. J’ai debuggé via les logs Unity et reconstruit les
MapChunkà la volée, et ça tient. - Décompilation du jeu via ILSpy pour comprendre les API internes. Le système de couleurs passe par un
ReligionColorsLibrary, les traits par unReligionTraitLibrary, la conversion d’un fidèle paractor.setReligion(). Sans la décompilation, c’était du grattage pur.
L’orchestrateur (Node.js / TypeScript)
C’est le cerveau de la simulation. La boucle de tick tourne comme ça : pause du jeu → snapshot du monde → conseil des dieux (3 rounds de débat, Sonnet) → réflexion parallèle des 4 dieux (Haiku) → validation des actions par budget → exécution via MCP → reprise du jeu.
Quelques points sur lesquels je me suis arrêté un moment :
- Le Divine Power. Chaque dieu accumule des points basés sur un ratio
followers / total mondial. Les points sont stackables sur 10 ticks, et chaque action a un coût fixe (1 point pour unbless, 6+ points pour ajouter un trait de religion). Le serveur enforce les coûts, du coup, si un dieu triche, ses actions sont rejetées en bloc. C’est ce qui a fini par donner un vrai équilibrage, j’en parle plus bas. - Multi-religion. Chaque dieu gère 5 à 7 religions en round-robin, et sa puissance cumule tous ses fidèles. Ce qui fait que la domination d’un dieu est directement corrélée au nombre de civilisations qui le vénèrent.
- Le conseil des dieux. Trois rounds de débat séquentiel via Claude Sonnet, le dieu le plus puissant parle en premier, et le résumé persiste dans le prompt jusqu’au conseil suivant. Ça crée une espèce de mémoire politique entre les sessions, ce qui est exactement ce que je cherchais.
- Interactions dieu-vs-dieu. Sabotage pour voler des points à un rival, bouclier divin, provocation, empowerment d’alliés, vol de fidèles. Typiquement le genre de choses qui émerge tout seul dès qu’on leur donne les outils.
- Persistance SQLite. Chaque pensée, chaque prompt envoyé, chaque action, chaque snapshot du monde est sauvegardé tick par tick. Au redémarrage du serveur, tout est restauré via un événement
sim:hydrate, ce qui permet de rejouer froidement une partie en entier des semaines après.
Le dashboard React
Interface temps réel pour observer la simulation et intervenir si besoin.
- Sidebar avec les avatars des dieux, toutes leurs religions, followers, et une barre de puissance divine.
- Dashboard principal : population par race, followers par dieu (stacked area), puissance divine dans le temps, table des royaumes (roi, religion, dieu protecteur, population, villes).
- Panneaux dieux : plan stratégique à 10 ans, pensées internes, actions récentes avec un badge de coût en points, actions rejetées barrées, et un mode debug complet avec le prompt envoyé et la réponse brute de Claude. Très utile pour comprendre pourquoi un dieu fait n’importe quoi.
- Conseil : log des débats avec avatars colorés et archetype.
- Replay : slider tick par tick, vue détaillée de chaque événement, pensées des dieux dépliables avec prompt et réponse côte à côte.
- Overgod : panneau d’intervention directe, pour lancer des décrets aux dieux, des actions rapides, ou appeler un outil MCP à la main.
- Action Feed : flux temps réel avec icônes, badge de coût, raison de l’action, et nom de la créature ciblée.
Ce que j’ai retenu
Les LLM sont des joueurs médiocres sans garde-fous. C’est probablement l’enseignement le plus net du projet. Sans budget de points ni validation serveur, les dieux faisaient la paix mondiale en un clic et convertissaient des armées entières gratuitement. L’équilibrage est venu de contraintes strictes : coûts fixes, budget limité, rejet des actions trop chères, et mémoire des échecs passés dans le prompt. Une fois qu’on encadre proprement, le jeu redevient intéressant.
L’impact réel est le plus dur à obtenir. Les dieux préfèrent les petites actions (bénir une personne, convertir un fidèle) aux grosses (ajouter un trait de religion qui change tout le gameplay pour des milliers de fidèles). Ce qui fait que la croissance naturelle du jeu écrase l’intervention divine, du coup, il faut activement pousser les IA vers les actions à fort impact. C’est contre-intuitif au départ, mais ça fait sens : une action coûteuse, c’est un risque à court terme pour un bénéfice à long terme, et les LLM raisonnent assez mal sur ce genre d’arbitrage sans qu’on les guide.
La persistance n’est pas optionnelle. J’ai commencé avec des fichiers JSON/JSONL, évidemment, et j’ai migré vers SQLite quand j’ai réalisé qu’un refresh faisait tout perdre. Maintenant chaque pensée de chaque dieu est traçable, rejouable, analysable. C’est typiquement le genre d’investissement qu’on repousse et qu’on regrette après.
Le modding est un terrain de jeu idéal pour l’IA. WorldBox expose assez d’API pour créer des systèmes complexes sans toucher au code source, et la décompilation via ILSpy a été cruciale pour comprendre les mécanismes internes (couleurs de religion, traits, pathfinding). C’est un format intéressant pour tester ce que les IA peuvent faire dans un environnement non trivial mais contraint.
Haiku + Sonnet, le bon compromis. Haiku pour les 800+ appels d’actions par simulation (pas cher, suffisant pour sortir du JSON structuré), Sonnet pour les ~50 sessions de conseil (meilleur dialogue, plus de personnalité, et ça se sent vraiment sur les débats). Coût total estimé : environ 5 à 10 dollars pour 1000 ans de simulation. Pour le coup, c’est ce genre de chiffres qui rend le projet jouable en side project.
Contexte
Projet personnel, développé en une session intensive avec Claude Code. L’idée vient de ma passion pour les simulations émergentes et de la question : que se passe-t-il quand on donne de l’autonomie à des agents IA dans un système complexe, avec des règles strictes mais de la marge pour improviser ?
Le code du mod C#, de l’orchestrateur TypeScript et du frontend React a été écrit intégralement via Claude Code, débugage compris (crash de pathfinding, API de couleurs des religions, parsing JSON des réponses Haiku). Pas mal d’itérations sur les prompts des dieux, mais assez vite convergent sur le reste.
Stack technique
| Composant | Technologies |
|---|---|
| Mod WorldBox | C# (.NET 4.8), NeoModLoader, Unity Engine |
| Orchestrateur | Node.js, TypeScript, tsx |
| IA des dieux | Claude Haiku 4.5 (actions) + Claude Sonnet 4 (council), via Anthropic SDK |
| Persistance | SQLite (better-sqlite3), WAL mode |
| Frontend | React 18, Vite 8, TypeScript, Tailwind CSS 4, Recharts, Zustand, Framer Motion |
| Communication | HTTP JSON-RPC 2.0 (MCP), WebSocket (ws), Express |
| Analyse | ILSpy (décompilation du jeu) |
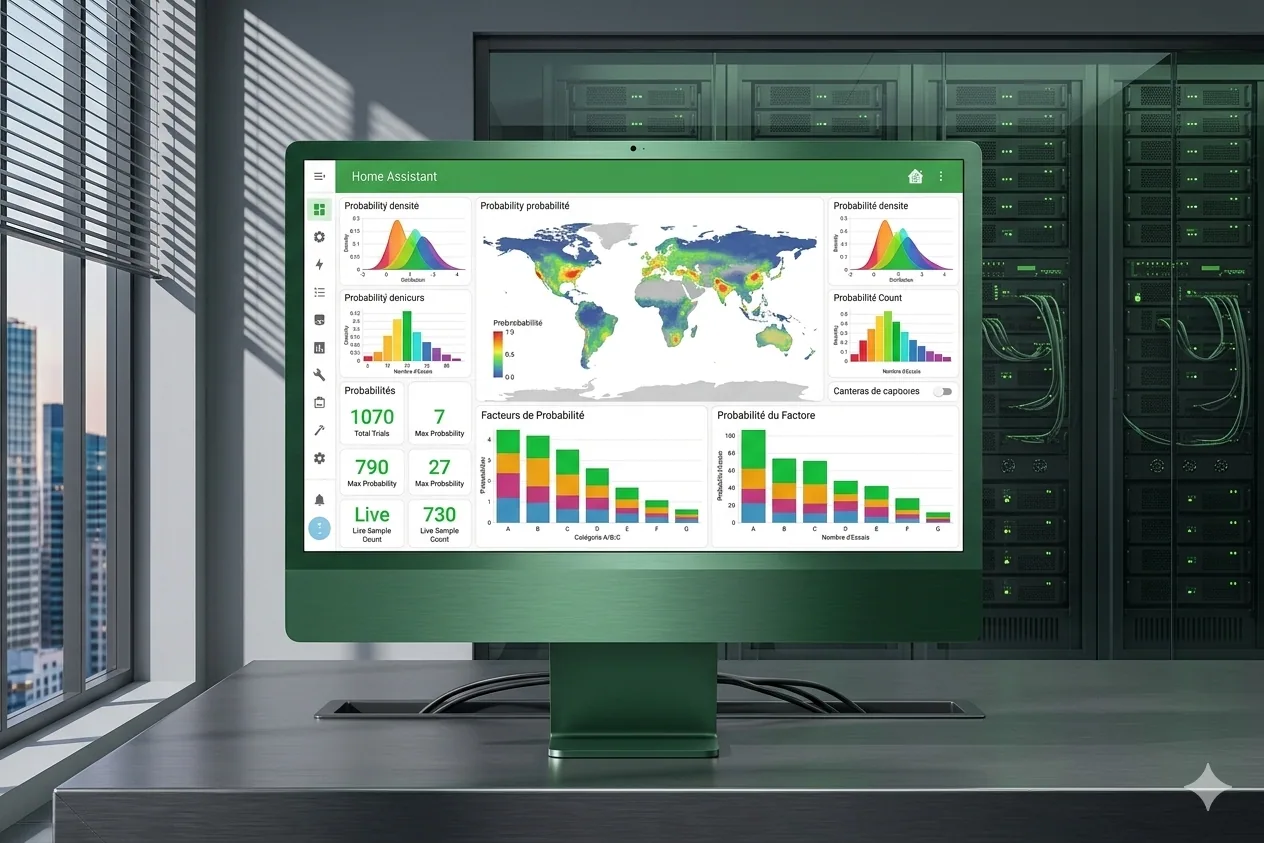
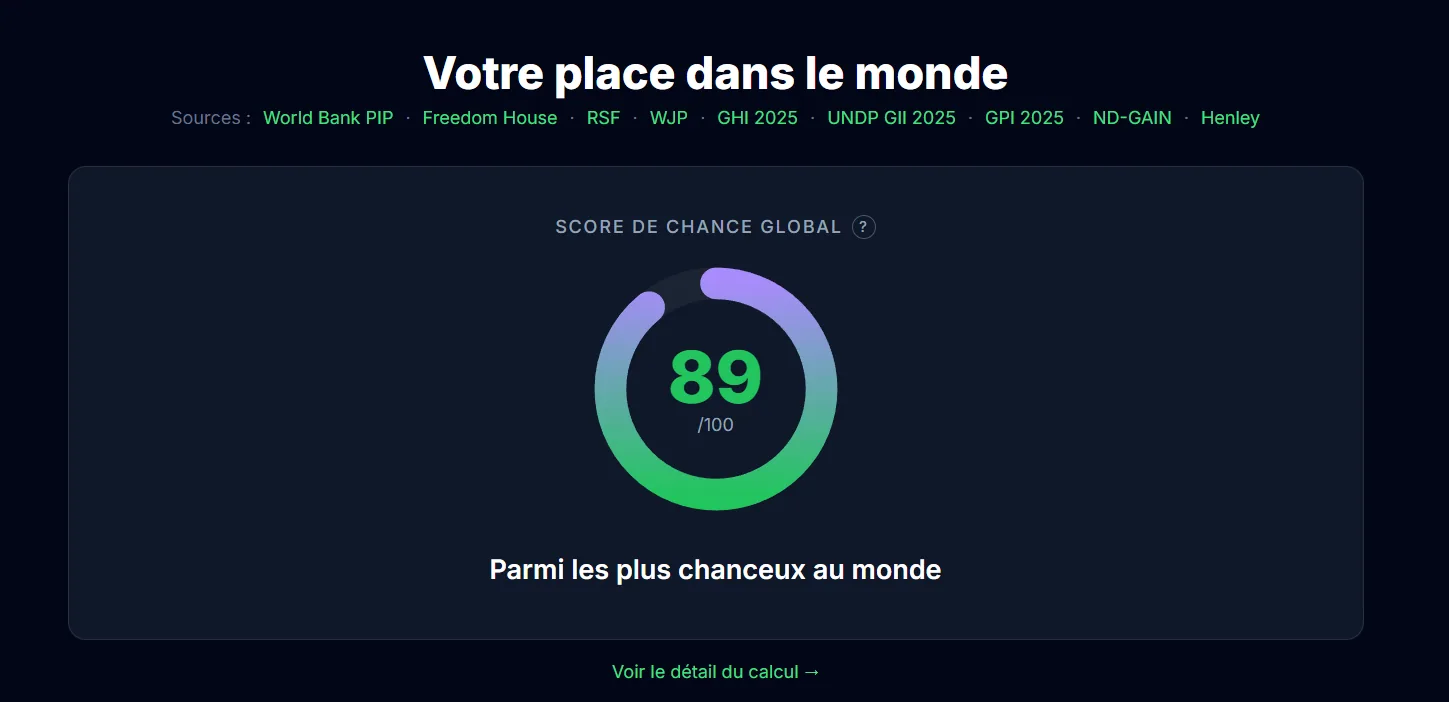
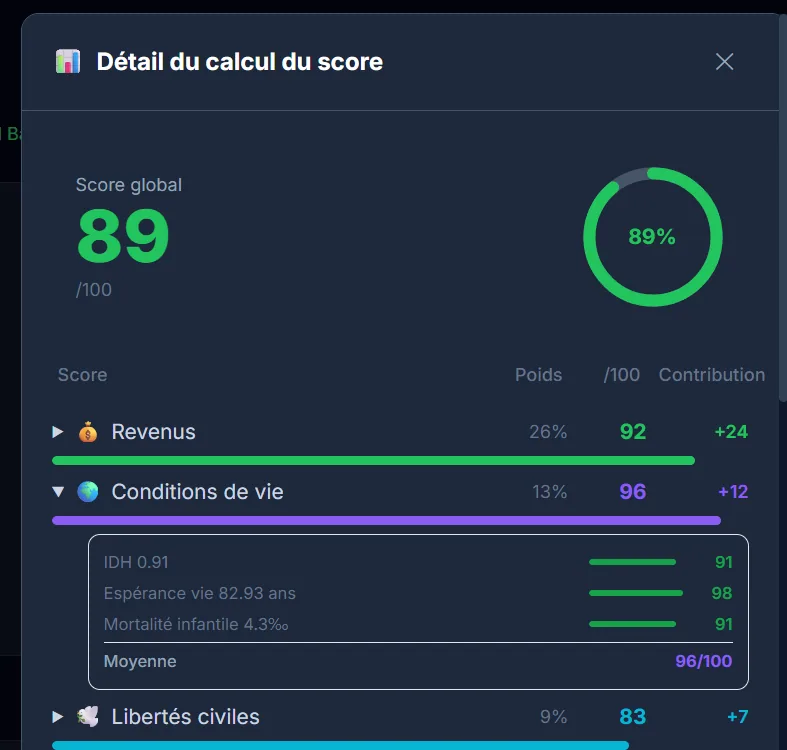
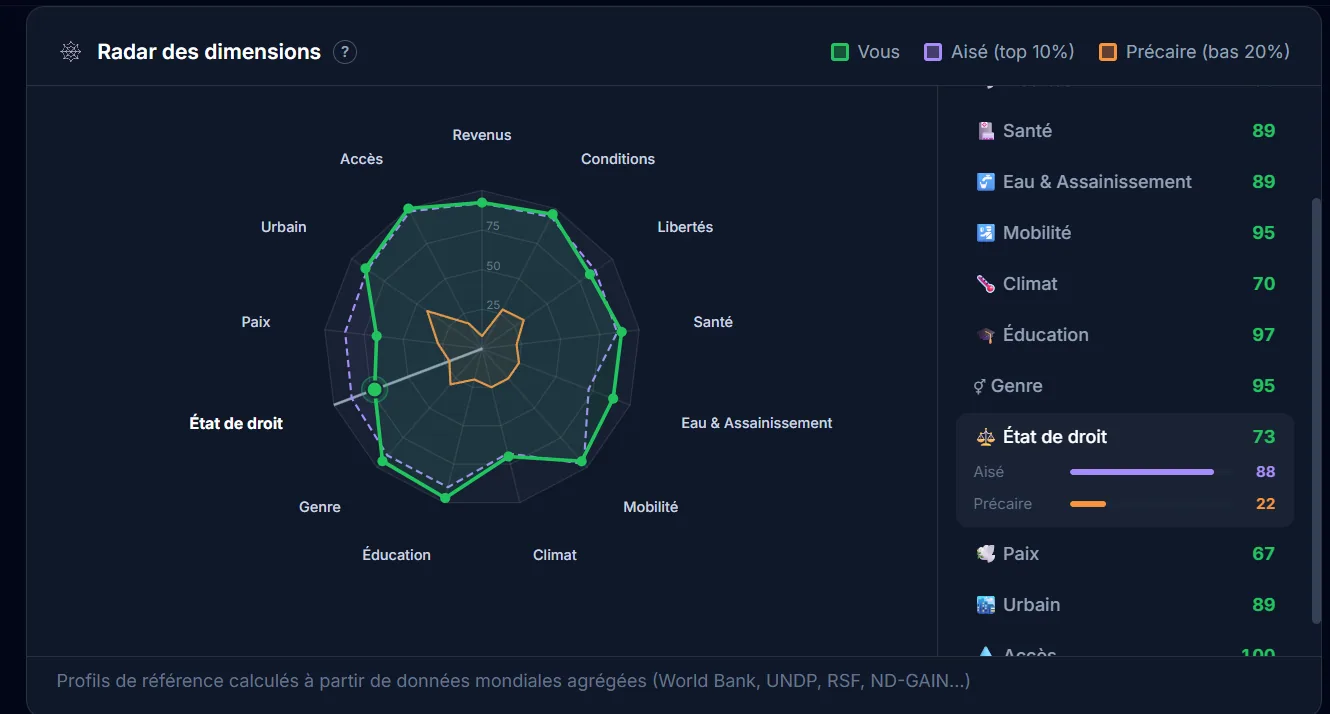
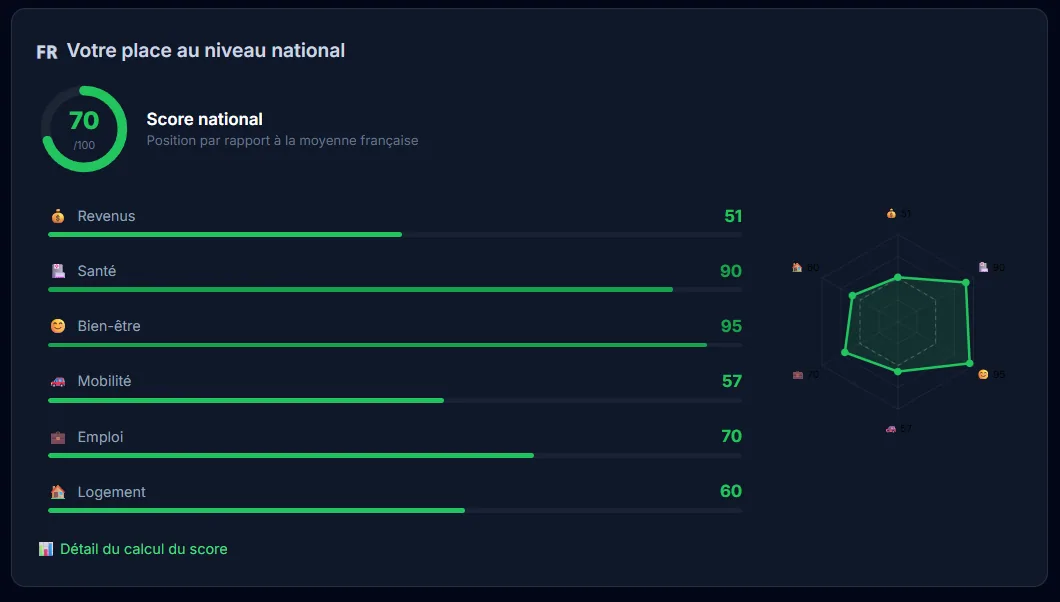
How Am I Lucky, une visualisation de la chance par les chiffres
Application web interactive de visualisation de probabilités et statistiques de chance avec React, D3.js et Framer Motion.
Le projet
How Am I Lucky, pour le coup, c’est une plateforme qui permet de comparer sa situation sur une cinquantaine d’indicateurs pour mesurer la « chance » qu’a une personne. Une sorte de boussole pour voir où on se situe dans le monde, à travers des visualisations interactives. Il y a évidemment quelques biais méthodo (notamment sur le choix des indicateurs), mais le résultat est assez parlant, notamment pour remettre en perspective des choses qu’on tient pour acquises.
Mes contributions
Développement complet : frontend React avec des visualisations D3.js et Recharts, animations Framer Motion, backend Express, et pipeline de données Python pour alimenter les environ 50 indicateurs. Mise en place des tests avec Vitest. L’idée étant que la partie données puisse évoluer sans refaire le front.
Ce que j’ai retenu
Faire parler des données statistiques de manière visuelle et accessible, c’est quelque chose qui reste un vrai défi. Combiner D3.js et Recharts, pour le coup, donne des résultats très complémentaires : D3 pour les trucs sur mesure, Recharts pour les charts plus standards sans perdre de temps. Et la séparation pipeline Python côté data et frontend React côté affichage, ça fonctionne très bien, notamment quand on ne veut pas régénérer la data à chaque fois.
Contexte
Projet personnel. L’idée étant de rendre tangible un concept abstrait, c’est-à-dire la chance, à travers des données concrètes et des visualisations interactives. C’est un exercice qui a évidemment ses limites, mais qui marche plutôt bien comme déclencheur de réflexion.
Aperçu de l’application
Technologies utilisées
-
React 18 / Vite
-
D3.js / Recharts
-
Framer Motion
-
Express.js
-
Tailwind CSS
-
Python
-
Vitest / Testing Library
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
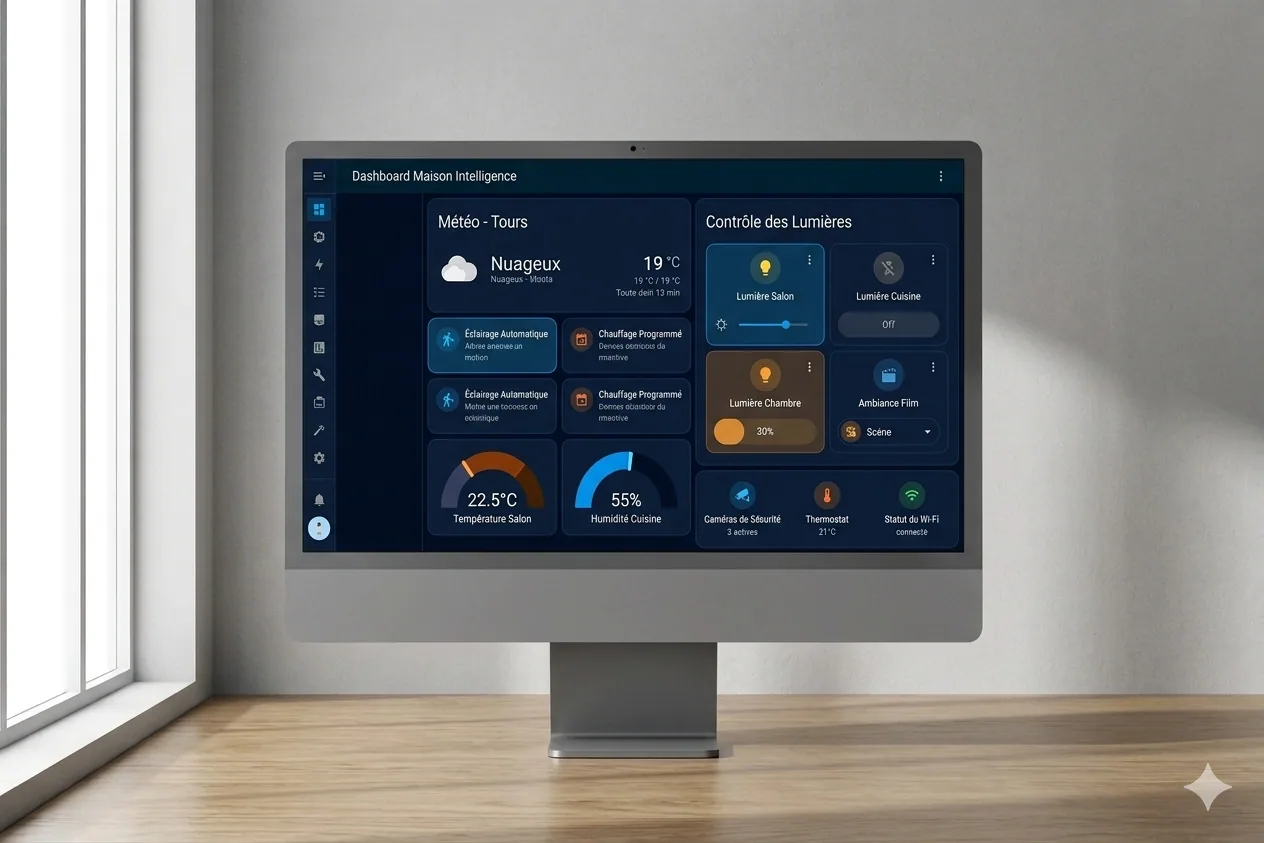
Home Assistant × Claude, la domotique augmentée par l’IA
Système de gestion Home Assistant augmenté par Claude, permettant de créer des automations domotiques en langage naturel avec validation multi-couche.
Le projet
Alors, pour le coup, c’est un système qui connecte mon installation Home Assistant à Claude pour accélérer considérablement la gestion de ma domotique. Concrètement, ça me permet d’accéder rapidement à mon installation, d’y ajouter ce qu’il me manque et de gagner un temps colossal sur la création d’automations. Fini les heures passées à écrire du YAML à la main, ce qui fait que je peux enfin passer du temps sur ce qui m’intéresse vraiment, c’est-à-dire les scénarios eux-mêmes.
Mes contributions
Développement complet du framework : outils de validation multi-couche, intégration du registre d’entités, hooks pre-commit automatisés, scripts d’installation pour Mac et Windows. J’ai aussi mis en place une suite de tests et tout l’outillage de qualité de code habituel (Black, isort, flake8, mypy, pylint). L’idée étant que le projet tienne debout tout seul, notamment quand je n’y reviens pas pendant quelques semaines.
Ce que j’ai retenu
L’intégration d’un LLM dans un workflow concret de développement, ça change vraiment la donne en termes de productivité. Évidemment, ça ne remplace pas la réflexion, mais ça enlève beaucoup de friction. La validation multi-couche, pour le coup, c’est essentiel quand on génère de la configuration automatiquement, parce qu’un YAML cassé sur Home Assistant peut faire tomber pas mal de choses d’un coup. Et Home Assistant, sous le capot, c’est un écosystème très riche, mais complexe à maîtriser, ce qui prend du temps.
Contexte
Projet personnel. La configuration Home Assistant en YAML, c’est puissant, mais chronophage et sujet aux erreurs. L’idée étant de combiner IA et domotique pour automatiser ce qui peut l’être, sans se priver de la puissance du système en dessous.
Technologies utilisées
-
Python 3.12+
-
Home Assistant / YAML
-
Claude Code (IA)
-
Voluptuous / PyYAML
-
pytest / pre-commit
-
Black / isort / flake8 / mypy / pylint
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
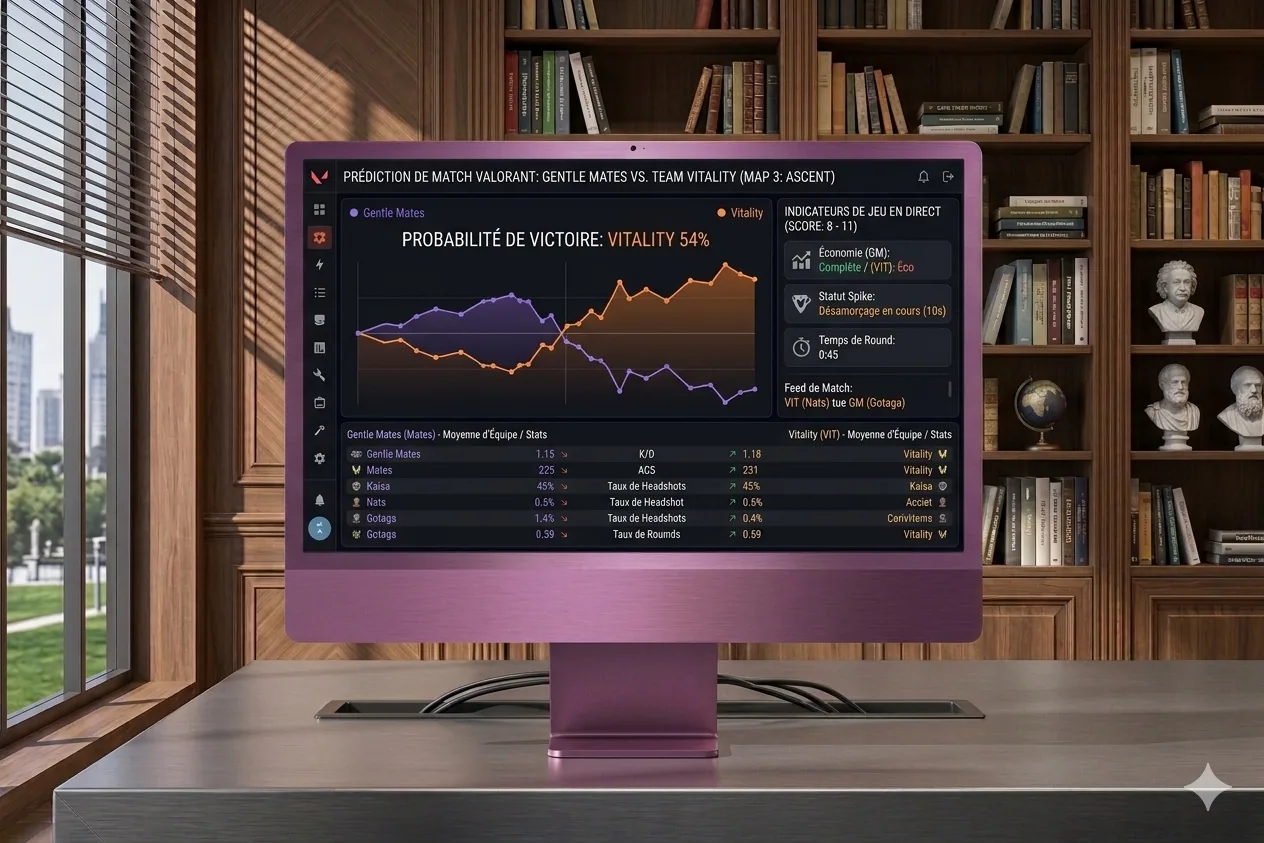
LoL Predict, une prédiction de matchs par ML
Prédiction en temps réel des probabilités de victoire pendant une partie de League of Legends, inspiré des overlays esport.
Le projet
LoL Predict, pour le coup, c’est la continuité de BestPick, mais avec une ambition un peu différente. L’idée étant d’avoir en temps réel, pendant une partie en cours, les probabilités de victoire, un peu comme ce qu’on voit dans les retransmissions esport. Savoir à quel moment une condition a basculé, quand on vient de perdre quelque chose d’important, ce genre d’insights. Du coup, j’ai fini par un peu mettre le projet en pause avec le temps, mais le concept reste sympa, et je pourrais y revenir plus tard avec plus de recul.
Mes contributions
Développement du collecteur de données via l’API Riot Games (riot_api_client, storage_client), analyse exploratoire en Jupyter, et implémentation de modèles de prédiction.
Ce que j’ai retenu
Appliquer du machine learning à des données de jeu vidéo, c’est passionnant mais complexe. La qualité des données en temps réel et le volume nécessaire sont de vrais défis, notamment si on n’a pas un gros stockage sous la main. C’est aussi un projet qui m’a appris à reconnaître quand il faut savoir mettre quelque chose en pause, parce que s’acharner n’est pas toujours la bonne stratégie, évidemment.
Contexte
Projet personnel, dans la continuité de BestPick. Inspiré par les overlays de probabilités en direct qu’on voit dans l’esport professionnel, qui sont typiquement le genre de chose qui fait très envie une fois qu’on les a vus en stream.
Technologies utilisées
-
Python
-
UV (package manager)
-
Riot Games API
-
Jupyter Notebooks
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
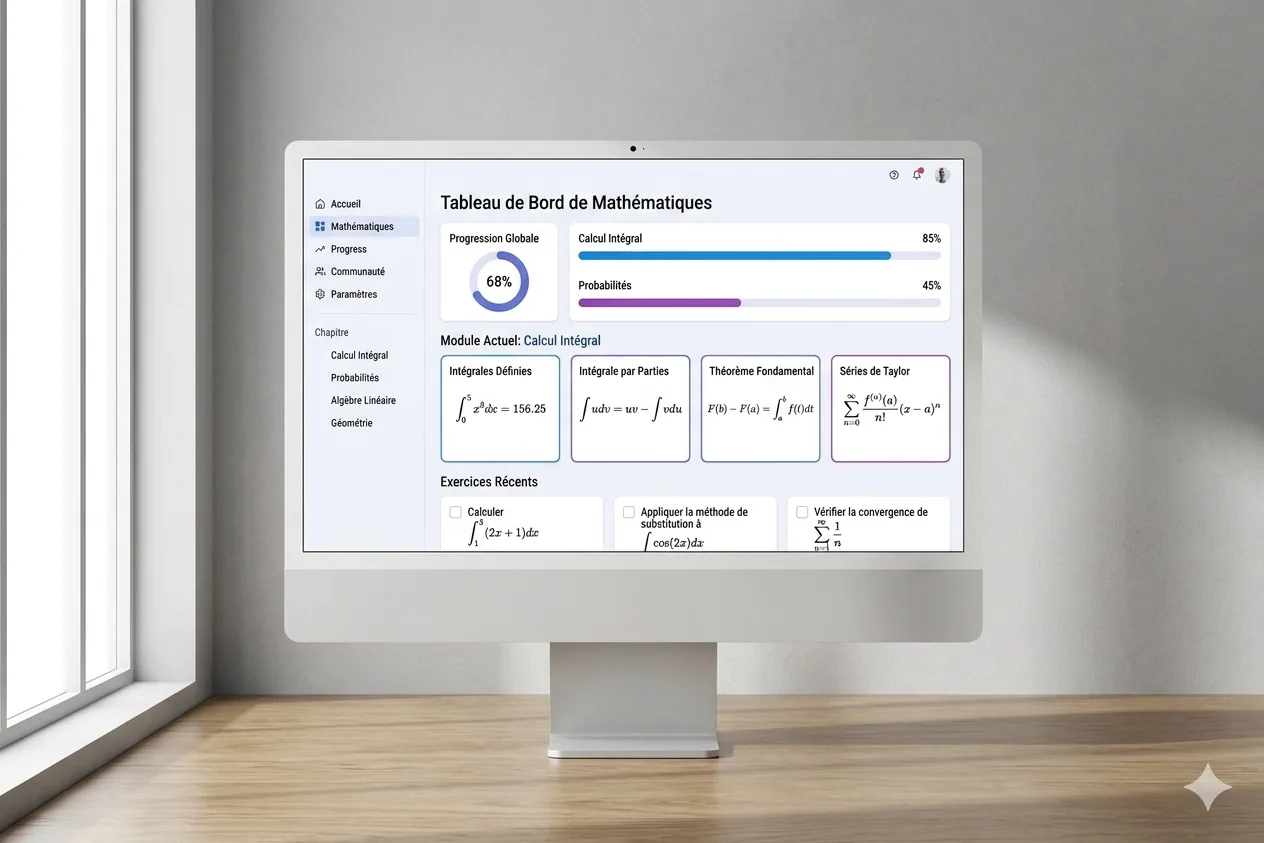
Mathelearning, une plateforme d’apprentissage des maths
Application web d’apprentissage des mathématiques pour la Data Science, avec comptes utilisateurs, suivi de progression et quiz interactifs.
Le projet
Mathelearning, pour le coup, c’est une plateforme web que j’ai montée pour me remettre aux mathématiques, orientée Data Science. C’est à la fois une appli de révision, une plateforme de cours structurés avec des exercices et du suivi de progression, et un outil de quiz. Le tout dans une seule interface, conçue pour rendre l’apprentissage efficace, et surtout un minimum motivant, parce que se remettre aux maths seul, c’est quelque chose qui peut vite se relacher si rien ne tient le fil.
Mes contributions
Conception et développement complet de la plateforme : architecture SPA avec API REST, système de comptes utilisateurs et authentification JWT, rendu de formules mathématiques avec KaTeX, suivi de progression par chapitre, tableau de bord, timer Pomodoro, système de badges et quiz interactifs. L’idée étant d’avoir un tout en un cohérent, plutôt qu’un empilement d’outils externes.
Ce que j’ai retenu
La combinaison cours, exercices et gamification, c’est vraiment efficace pour se motiver à apprendre. Du coup, j’ai aussi approfondi l’architecture SPA avec Node.js et Express, la gestion d’authentification JWT, et la persistance avec sql.js (SQLite embarqué dans Node), ce qui est une approche un peu moins courante mais qui marche bien pour un projet perso sans serveur de base de données dédié.
Contexte
Projet personnel. J’avais besoin d’un outil structuré pour me remettre à niveau en maths appliquées à la Data Science, et évidemment rien d’existant ne me convenait vraiment. C’est typiquement le genre de truc qu’on se fabrique quand on a une idée précise de ce qu’on veut.
Screens
Technologies utilisées
-
Node.js / Express.js
-
SQL.js (SQLite)
-
JWT / bcryptjs
-
KaTeX
-
HTML / CSS / JavaScript vanilla
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
Programme Maire, un test de compatibilité pour les municipales
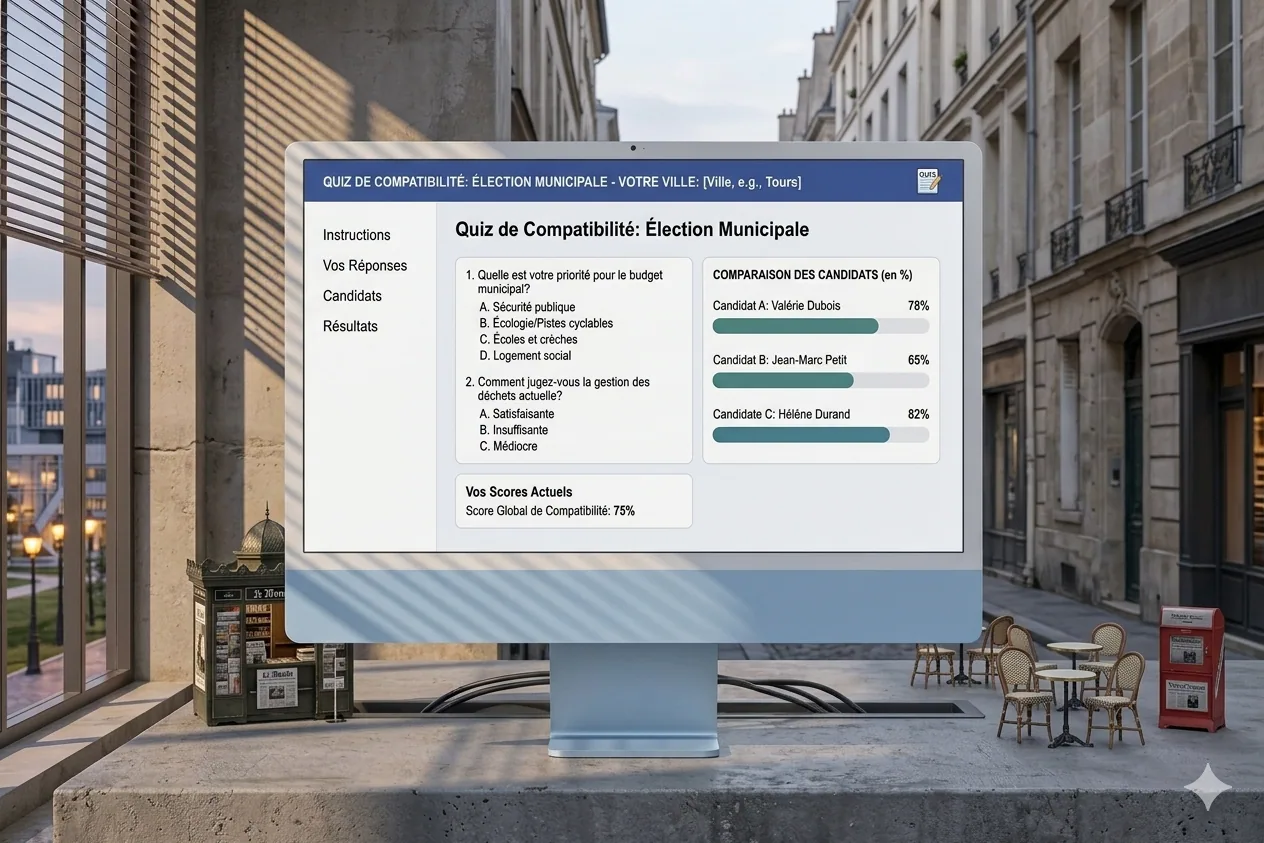
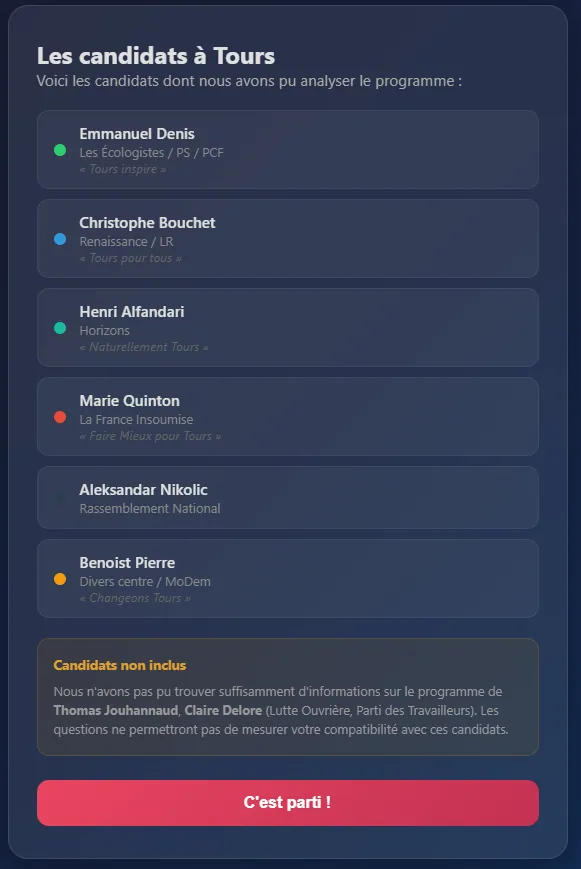
Outil de compatibilité électorale pour les municipales : répondez à des questions et découvrez votre taux d’affinité avec chaque candidat.
Le projet
C’est quelque chose que j’ai toujours voulu avoir, pour le coup : connaître mon taux de compatibilité avec les différents candidats. Ce genre d’outil existe pour les présidentielles et les législatives, mais jamais pour les municipales. Du coup, j’ai monté le mien : je récupère les programmes des différents candidats, j’en extrais des questions clés, et l’utilisateur y répond pour découvrir sa compatibilité avec chaque candidat. Il y a évidemment une part d’interprétation, parce que les positions municipales sont rarement très précises, mais c’est suffisamment intéressant pour se faire une idée, notamment quand on ne connaît pas tous les candidats en détail.
Mes contributions
Conception et développement complet : récupération et analyse des programmes, création du système de questions et réponses, algorithme de scoring de compatibilité, et interface de présentation des résultats. L’idée étant de garder quelque chose de très direct, notamment pour ne pas perdre l’utilisateur en route.
Ce que j’ai retenu
Extraire des positions politiques claires à partir de programmes municipaux, c’est un vrai défi, parce que beaucoup de sujets restent vagues. Le système de scoring, du coup, doit être transparent pour être crédible, ce qui veut dire expliciter les pondérations et les choix d’interprétation. Et c’est un projet qui touche à l’engagement citoyen, ce qui le rend particulièrement motivant, même si évidemment, il faut rester humble sur la portée réelle d’un outil comme ça.
Contexte
Projet personnel et citoyen, lancé un peu tard pour les élections (je n’ai pas eu le temps de le rendre public à temps, pour le coup), mais le concept reste pertinent et réutilisable pour les prochaines échéances.
Screens


Technologies utilisées
-
JavaScript vanilla
-
HTML / CSS
L’image d’illustration a été générée par Nano Banana (Google), parce que je n’ai plus le modèle de mockup que j’utilisais auparavant. Du coup, il ne s’agit pas d’une capture d’écran de l’outil.
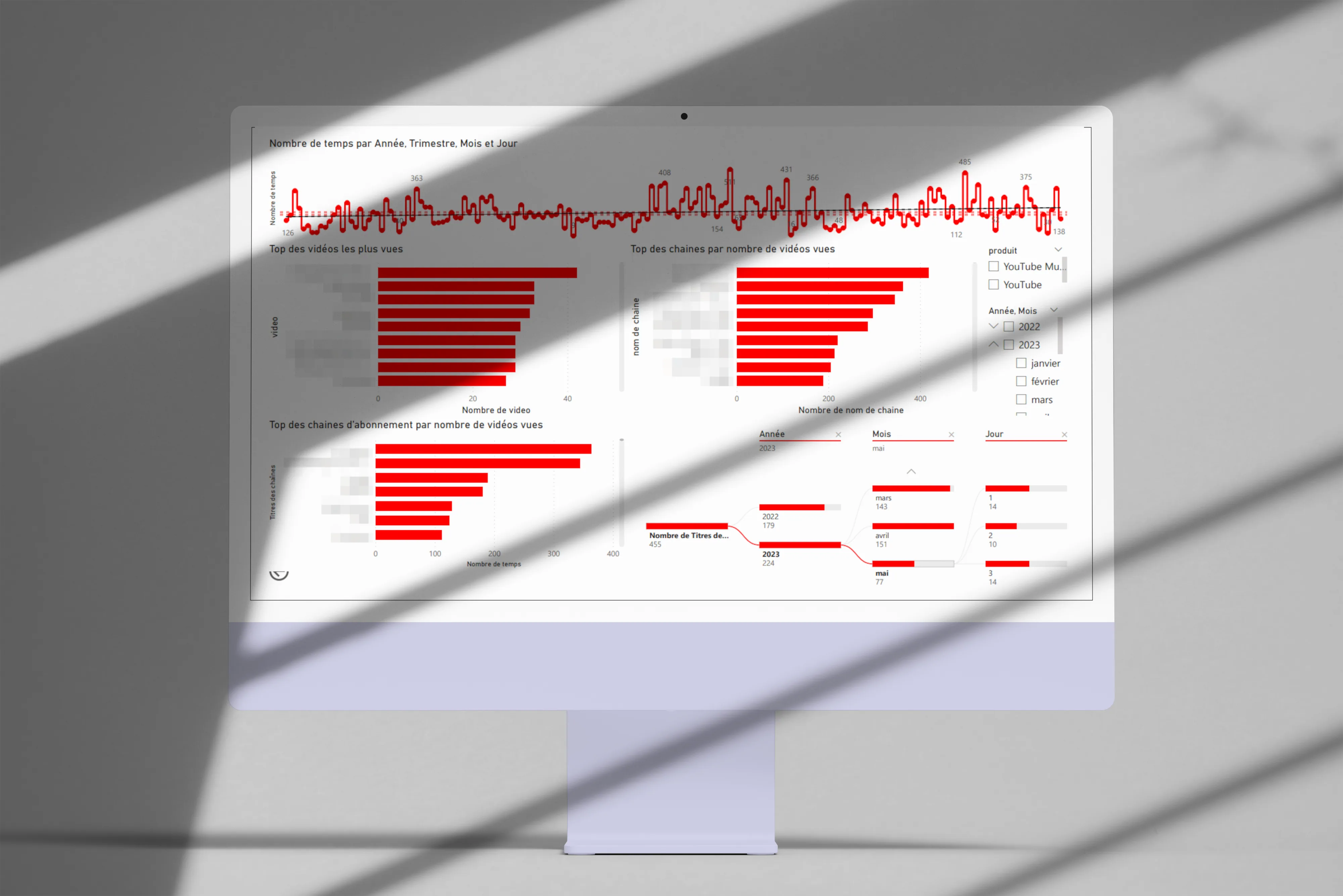
Visualisation de données YouTube
Analyse et visualisation de ma consommation YouTube avec PowerBI et Python.
Le projet
Depuis quelques mois, ma consommation YouTube a pas mal évolué. Les Shorts ont fait leur apparition dans mon quotidien, alors que je les évitais jusque-là, et c’est quelque chose qui m’a intrigué assez vite. Du coup, cette petite curiosité m’a poussé à analyser mes habitudes de visionnage pour mieux les comprendre, notamment pour voir si je regardais vraiment autant de Shorts que mon impression me le laissait croire.
Les données
J’ai récupéré mon historique complet via Google Takeout, puis monté une application PowerBI pour visualiser mes données de consommation. L’idée étant d’avoir quelque chose d’interactif, pour pouvoir creuser au fil des questions qui se posent.
Premières visualisations
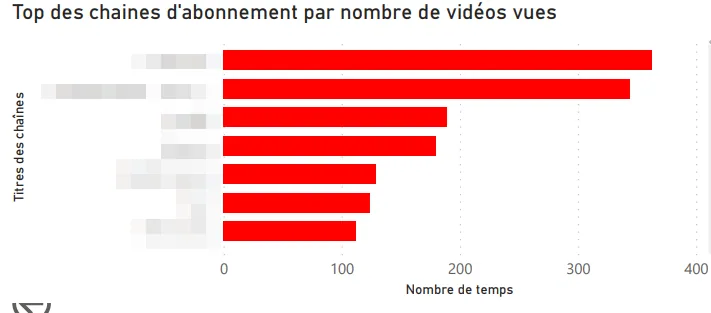
Voici les axes que j’ai explorés en premier :
-
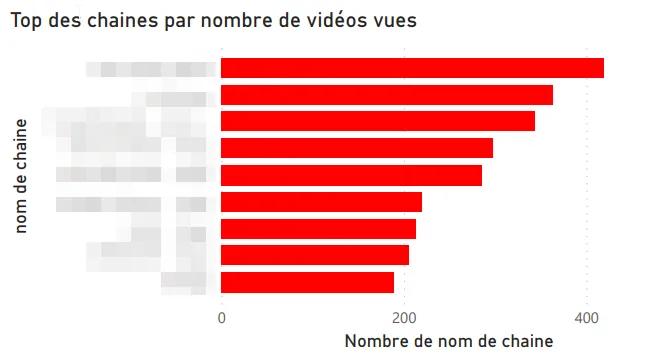
Top des chaînes par nombre de vidéos vues.
-
Top des chaînes auxquelles je suis abonné.
-
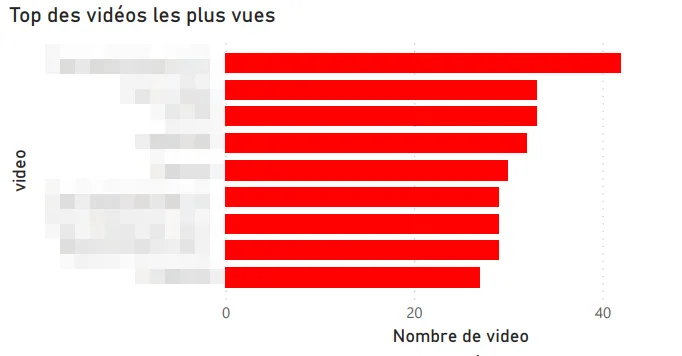
Vidéos les plus regardées.
-
Répartition temporelle (année, trimestre, mois, jour).
Shorts contre vidéos classiques
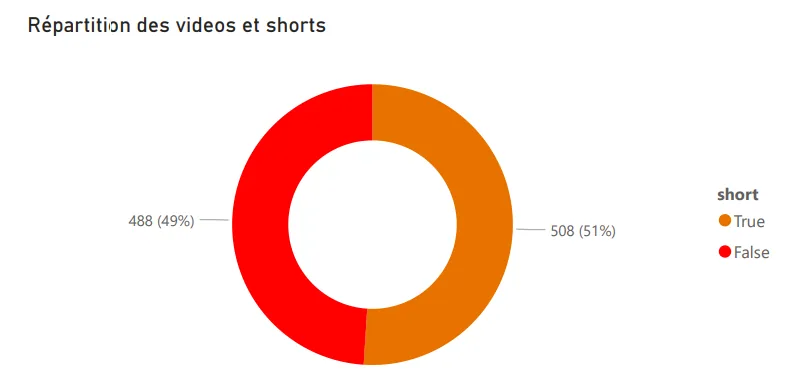
Premier problème, pour le coup : YouTube ne distingue pas les Shorts des vidéos classiques dans les données exportées. En creusant, j’ai découvert que l’URL des Shorts contient un chemin /shorts/[id], ce qui m’a permis de les identifier et de créer une visualisation dédiée à cette répartition. C’est pas très élégant comme technique, mais ça marche bien.
Autres visualisations
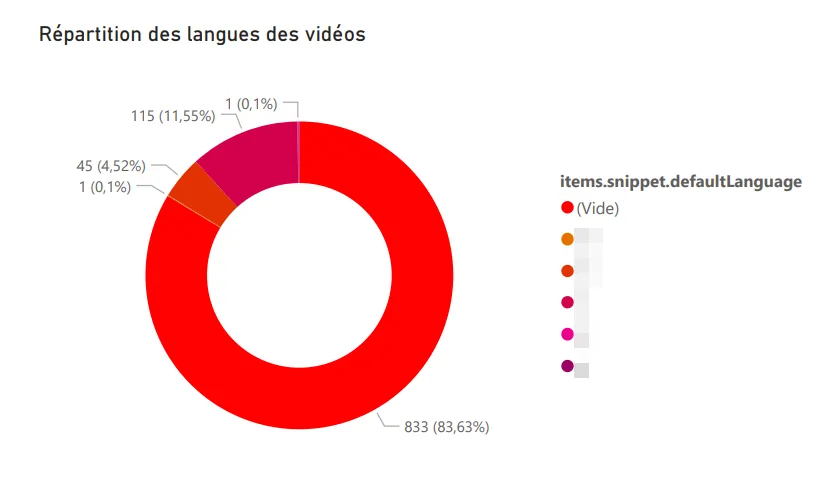
Distribution des langues. En réutilisant la logique de mon projet Any%English, j’ai identifié la langue de chaque vidéo regardée : français, anglais, allemand, japonais (probablement les Shorts, d’ailleurs).
Nuage de mots. Généré à partir des descriptions des vidéos regardées, il fait ressortir mes thématiques récurrentes : musique, jeux vidéo, voyages. Rien de très surprenant pour le coup, mais c’est toujours sympa de le voir chiffré.
Catégories les plus regardées. Musique, jeux vidéo, et divertissement arrivent en tête.
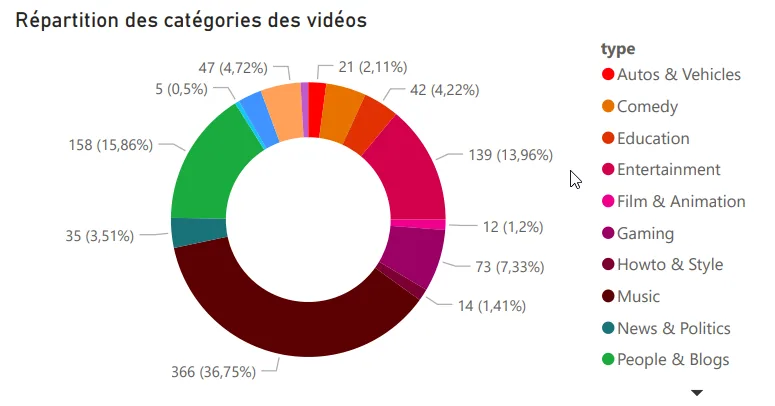
Motivations
Ce projet répondait à une vraie question personnelle sur mes habitudes numériques, et en même temps il m’a permis de monter en compétences sur PowerBI, que je connaissais moins bien que Tableau Software. Du coup, c’est un double bénéfice, ce qui est toujours agréable sur un projet perso.
Technologies utilisées
-
PowerBI
-
Python
-
YouTube Data API v3
Conscious, une application anti-gaspillage alimentaire
Application web de vente de paniers repas anti-gaspillage, réalisée en équipe avec Spring Boot.
Le projet
Dans le cadre de ma 3ème année de licence Informatique, nous avons conçu une application web permettant la vente de paniers repas pour lutter contre le gaspillage alimentaire. C’est un sujet qui nous tenait à cœur, et ça faisait un projet école un peu plus concret que d’habitude, ce qui fait que l’équipe était plutôt motivée.
En équipe de trois étudiants, nous avons adopté une méthode de travail Agile (Scrum) où chaque membre a exploré l’ensemble de la chaîne, du design au développement. L’idée étant que chacun monte un peu en polyvalence, notamment pour ne pas se retrouver bloqués si une personne manquait.
Mes contributions
-
Organisation et suivi du projet.
-
Développement de la partie administration et de la page d’accueil.
-
Création des maquettes graphiques et des éléments visuels.
Ce que j’ai retenu
Nous avons livré dans les temps, même si notre envie d’explorer des fonctionnalités techniques ambitieuses nous a coûté du temps, pour le coup. Ce projet m’a beaucoup appris sur la gestion d’équipe, la priorisation, et le fonctionnement du web à travers Spring Boot. Évidemment, on aurait pu être plus raisonnables sur le scope au départ, mais c’est typiquement le genre de leçon qu’on n’apprend qu’en s’y cassant les dents.
Contexte
Projet réalisé dans le cadre de la licence Informatique de l’université de Tours.
Technologies utilisées
-
Spring Boot / Java EE
-
JPA / Hibernate
-
MySQL
-
jQuery / Bootstrap 4
-
Maven / Git
Opinion Mining, une analyse de sentiments sur du texte
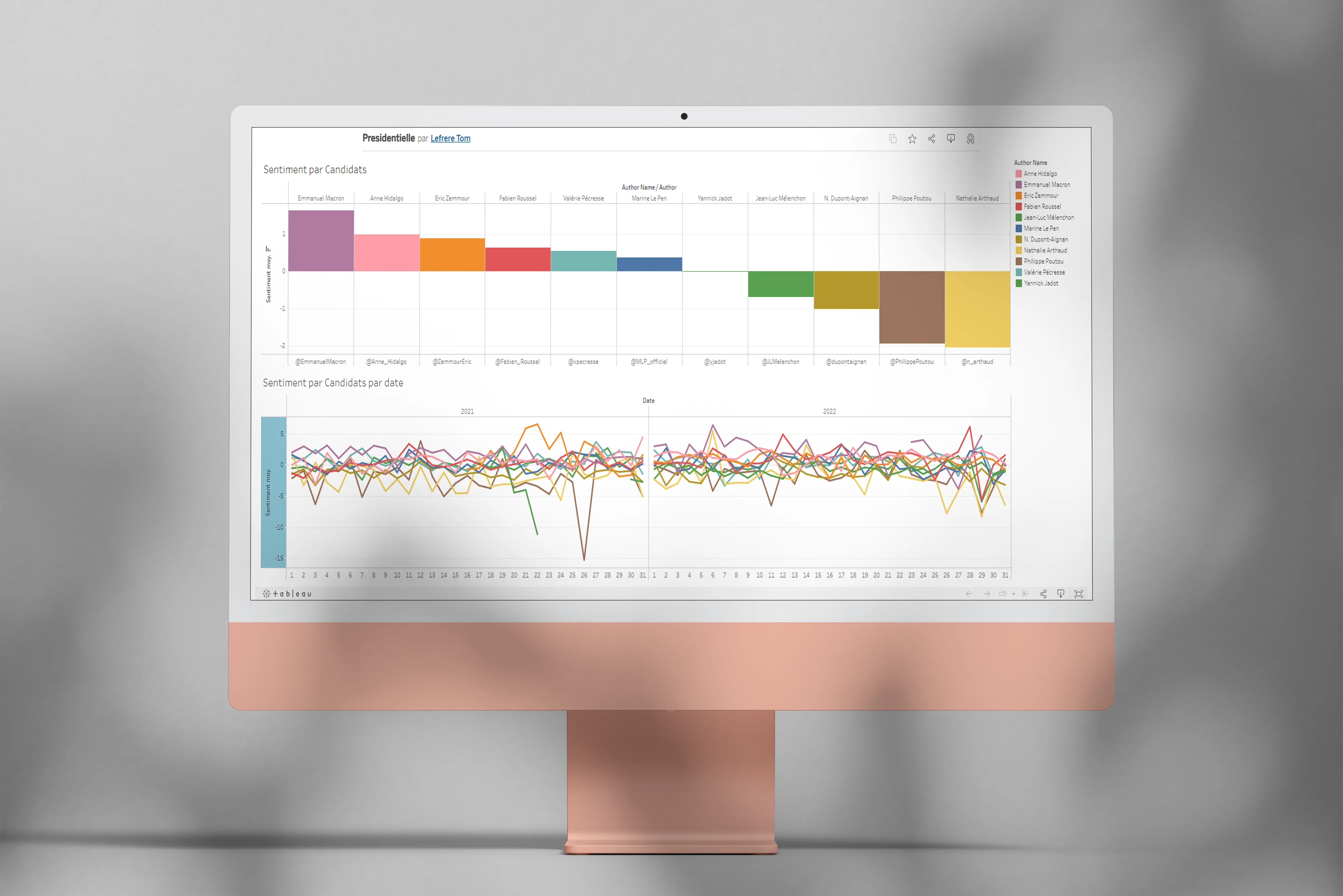
Exploration de l’analyse de sentiments sur des tweets et des textes avec Python et Orange DataMining.
Le projet
Ce projet universitaire avait pour objectif de répondre à deux questions assez fondamentales : qu’est-ce que l’analyse de sentiments, et comment peut-on l’appliquer concrètement ? Pour le coup, c’est le genre de sujet qui a l’air simple dit comme ça, mais qui devient beaucoup plus subtil dès qu’on regarde un vrai corpus.
Cas d’usage 1, les tweets de candidats à la présidentielle
En utilisant l’API Twitter, j’ai récupéré les 4 000 derniers tweets de plusieurs candidats pour analyser la tonalité de leur communication : positive, négative ou neutre. L’idée étant de voir si l’on peut caractériser une posture de campagne juste sur la charge émotionnelle des tweets.
Cas d’usage 2, les tweets sur l’Ukraine après l’invasion
Grâce à Orange DataMining et son intégration Twitter, j’ai analysé le sentiment global des tweets publiés sur le conflit ukrainien dans les jours suivant le début de l’invasion. C’est évidemment un sujet lourd, et les résultats sont à prendre avec beaucoup de prudence, notamment parce que l’analyse automatique passe mal l’ironie et la douleur.
Cas d’usage 3, l’analyse d’un webtoon
J’ai appliqué l’algorithme sur les textes du webtoon Eleceed pour en extraire les personnages principaux et analyser les sentiments associés aux dialogues. Les résultats étaient inégaux selon la complexité des phrases, ce qui fait que c’était pas totalement exploitable, mais l’expérience était riche en enseignements sur les limites du modèle.
Ce que j’ai retenu
L’opinion mining, c’est une technique d’extraction et de classification des opinions à partir de textes, utile notamment pour le suivi de tendances et la prédiction de comportements. Les résultats ne sont pas toujours directement actionnables, évidemment, mais ils offrent une lecture intéressante des dynamiques d’opinion, du coup c’est quelque chose qu’on peut intégrer à d’autres signaux plutôt que de s’appuyer dessus seul.
Contexte
Projet réalisé dans le cadre de la licence Informatique de l’université de Tours.
Technologies utilisées
-
Python
-
Orange DataMining
-
Tableau Software
-
Twitter API
GetSubscribedChannels, un export des chaînes YouTube
Script Python pour récupérer les images de ses chaînes YouTube abonnées via l’API YouTube v3.
Le projet
Alors, pour le coup, un ami m’a proposé de faire un tier list de nos YouTubeurs préférés pour échanger des recommandations. Le problème, c’est qu’aucun template disponible sur Tiermaker ne contenait toutes mes chaînes. Du coup, plutôt que de les ajouter manuellement à la main (ce qui aurait pris du temps pour un résultat moyen), j’ai adapté le code de mon projet Any%English pour automatiser la récupération des visuels de chaque chaîne.
Comment ça fonctionne
-
Export de mes abonnements depuis Google Takeout.
-
Lecture du fichier CSV contenant les IDs de chaînes.
-
Appel à l’API YouTube v3 pour récupérer l’image de chaque chaîne.
-
Téléchargement des images pour la création du template Tiermaker.
Résultat simple, rapide, et efficace. C’est typiquement le genre de micro-outil qu’on code en une soirée et qui finit par resservir plus souvent qu’on ne le pense.
Contexte
Projet personnel, né d’un besoin concret en quelques heures.
Technologies utilisées
-
Python
-
Requests / Pandas
-
YouTube Data API v3
Legermain, un site vitrine d’artisan
Site vitrine réalisé avec Symfony pour un artisan fictif, dans le cadre de la licence Informatique.
Le projet
Dans le cadre de ma 3ème année de licence Informatique, nous avons créé un site vitrine pour un artisan fictif. L’objectif était de concevoir et développer un portfolio complet pour mettre en valeur l’activité du client, avec la contrainte d’utiliser le framework Symfony. C’est quelque chose qu’on retrouve souvent en cours : un sujet qui a l’air simple, mais qui devient intéressant dès qu’on le prend au sérieux.
En groupe de 5 étudiants, nous avons travaillé en mode Agile sur 3 mois, à raison de 2 à 4 heures par semaine. Chaque membre a couvert l’ensemble de la chaîne, du design à la mise en ligne, ce qui fait que personne n’était complètement cantonné à un rôle.
Mes contributions
-
Organisation de l’équipe et gestion de projet.
-
Maquettes graphiques et éléments visuels.
-
Développement des pages Réalisations, Dashboard, et panneaux d’administration.
-
Extensions TWIG (partage, etc.).
-
Déploiement sur mon serveur.
Ce que j’ai retenu
Nous avons livré dans les temps, malgré notre goût pour l’exploration technique, ce qui n’était évidemment pas gagné d’avance. Ce projet m’a beaucoup apporté sur la gestion d’équipe et la compréhension du web avec Symfony, notamment sur tout ce qui touche aux templates et à l’organisation du code.
Contexte
Projet réalisé dans le cadre de la licence Informatique de l’université de Tours.
Technologies utilisées
-
Symfony / PHP / JavaScript
-
Adobe XD, Photoshop, Illustrator
Any%English, quelle part de YouTube je regarde en anglais ?
Script Python pour calculer le pourcentage de vidéos YouTube visionnées en anglais via l’API YouTube v3.
Le projet
Une question me trottait dans la tête depuis un moment : depuis que j’utilise YouTube, quel pourcentage de mes vidéos j’ai visionnées en anglais ? C’est quelque chose d’un peu futile, évidemment, mais qui me paraissait assez parlant pour mesurer mon « exposition » quotidienne à la langue.
Après avoir vérifié les possibilités de l’API YouTube, pour le coup, j’ai constaté qu’elle ne permettait de récupérer que 50 vidéos d’historique à la fois depuis la v3. Pas suffisant pour mon volume de consommation, du coup il fallait ruser un peu.
La solution
-
Export de l’historique complet via Google Takeout.
-
Lecture et traitement des données avec Pandas.
-
Envoi des IDs vidéo par batchs de 50 à l’API YouTube v3.
-
Récupération du champ
defaultAudioLanguagepour chaque vidéo. -
Calcul du pourcentage final.
Résultat
Sur mes 16 000 dernières vidéos : 53 % en français, le reste principalement en anglais. C’est un peu plus équilibré que je ne le pensais, notamment parce que j’avais l’impression subjective d’être plutôt autour de 70/30 vers l’anglais.
Contexte
Projet personnel, né d’une simple curiosité sur mes habitudes numériques.
Technologies utilisées
-
Python
-
Scrapy / Pandas
-
YouTube Data API v3
DofusClassSelector, une analyse du ladder Dofus
Bot de scraping pour identifier les classes les moins jouées dans le ladder Kolizéum de Dofus.
Le projet
En reprenant le MMORPG Dofus, je devais choisir ma classe. Plutôt que de prendre une classe populaire, pour le coup, j’ai voulu jouer une classe peu représentée parmi les meilleurs joueurs. C’est un choix un peu à contre-courant, évidemment, mais qui rend la progression plus amusante, notamment parce que chaque matchup est moins répétitif.
Du coup, j’ai monté un bot qui scrape le ladder Kolizéum (classement des meilleurs joueurs solo) et analyse la distribution des classes pour identifier les moins jouées.
Ce que j’ai appris
Ce projet a été mon premier contact avec le web scraping et la gestion de données tabulaires. Une expérience vraiment enrichissante, qui m’a donné envie de continuer sur la data. C’est quelque chose qui a directement déclenché plusieurs autres projets derrière.
Contexte
Projet personnel, réalisé par curiosité et pour un usage pratique.
Technologies utilisées
-
Python
-
Selenium (scraping)
-
Pandas (analyse des données)
LunaSleep, la lune influence-t-elle ma qualité de sommeil ?
Analyse de la corrélation entre les phases lunaires et la qualité de mon sommeil via l’API Withings.
Le projet
Passionné de data et de domotique, pour le coup, j’ai voulu combiner les deux pour tester une hypothèse que mes parents m’ont toujours soumise : la lune influencerait la qualité du sommeil. C’est quelque chose que j’entends depuis toujours, et plutôt que d’accepter ou de rejeter cette idée sans preuves, j’ai décidé de le vérifier sur mes propres données.
Les données
Depuis plusieurs mois, j’utilise un capteur de sommeil Withings qui analyse la qualité de mes nuits. En combinant ces données avec les phases lunaires, l’objectif étant de déterminer s’il existe une corrélation observable, même si évidemment, il faut rester prudent parce que le volume de données est limité.
Ce que j’ai retenu
Ce projet m’a permis de progresser sur l’utilisation d’API Python et la gestion de séries temporelles avec Pandas, ce qui m’a beaucoup servi par la suite, notamment sur d’autres analyses perso.
Le projet est en cours. Les résultats seront publiés ici dès que possible.
Contexte
Projet personnel, motivé par la curiosité et l’auto-analyse.
Technologies utilisées
-
Python
-
Withings API
-
Pandas
Big4Craft, un site de tournoi Minecraft monté en urgence
Plateforme web créée en quelques heures pour gérer un tournoi Minecraft entre amis.
Le projet
Faisant partie d’un serveur multi-gaming entre amis, nous avons organisé un tournoi Minecraft. Pour centraliser les informations des épreuves et les rendre accessibles à tous les participants, j’ai monté une plateforme web simple et rapide, pour le coup. L’idée étant que chacun retrouve l’essentiel au même endroit, sans avoir à cliquer sur un message Discord vieux de deux semaines.
Ce qui a été réalisé
-
Création des contenus graphiques et textuels.
-
Installation et configuration du site.
-
Mise en ligne opérationnelle en quelques heures.
Contexte
Projet communautaire, réalisé pour une petite communauté de joueurs. Typiquement le genre de coup de main qu’on donne quand on a les outils sous la main, et ça rend l’événement beaucoup plus carré.
Technologies utilisées
- WordPress (template Colibri + extensions)
Université Populaire de l’Indre, une plateforme de cours
Conception et intégration d’une plateforme web pour digitaliser les cours, plannings et paiements.
Le projet
Contacté pour réaliser le site web de l’Université Populaire de l’Indre, j’ai travaillé en binôme avec un autre développeur junior sur une plateforme plutôt ambitieuse, pour le coup : digitaliser les cours, les plannings et les paiements de l’association. C’est typiquement le genre de mission qui a l’air simple sur le papier, mais qui révèle beaucoup de cas particuliers à l’usage.
Mes contributions
-
Recherches graphiques et choix de direction artistique.
-
Réalisation des maquettes.
-
Intégration du frontend.
Nous avons finalisé une version bêta fonctionnelle. Évidemment, le projet s’est arrêté prématurément suite à la fin du contrat, ce qui fait qu’il n’est pas allé jusqu’à la mise en production complète.
Contexte
Mission freelance pour l’Université Populaire de l’Indre.
Technologies utilisées
-
PHP (sans framework)
-
JavaScript
-
CSS
ExamApp, la planification des examens universitaires
Application Java de planification des examens pour le secrétariat de l’université de Tours, avec solveur de contraintes Optaplanner.
Le projet
Dans le cadre de ma 2ème année de licence Informatique, nous avons développé une application pour aider le secrétariat de l’université à planifier les examens, en tenant compte de nombreuses contraintes (salles, disponibilités, groupes, etc.). C’est le type de problème qui est simple à formuler mais, pour le coup, assez coriace à résoudre proprement.
En groupe de 5 étudiants, nous avons mis en place une méthode de travail collaborative avec une répartition claire des responsabilités. L’idée étant que chacun ait un périmètre, sans perdre la vue d’ensemble.
Mes contributions
-
Organisation de l’équipe et gestion de projet.
-
Maquettes graphiques.
-
Développement du solveur de contraintes avec Optaplanner.
Ce que j’ai retenu
Ce projet m’a beaucoup appris sur le travail en équipe et la gestion des ressources. Il m’a aussi permis, pour le coup, de prendre conscience de certaines de mes limites en leadership à l’époque, ce qui est évidemment toujours un peu inconfortable à admettre, mais c’est utile pour la suite. Nous avons néanmoins livré une version fonctionnelle dans les temps.
Contexte
Projet universitaire pour le secrétariat de l’université de Tours.
Technologies utilisées
-
Java
-
Optaplanner (solveur de contraintes)
Overbet, des paris amicaux sur l’esport Overwatch
Application web de paris amicaux autour de la ligue esport Overwatch, développée en deux versions.
Le projet
Overbet vient de la période où j’étais très actif dans la communauté esport Overwatch. Avec des amis, on faisait déjà des paris sur les matchs de l’Overwatch League, et je voulais créer une vraie interface graphique avec un système de score et de classement pour que tout le monde puisse y participer. Du coup, l’idée était de passer d’un fichier Excel un peu bancal à quelque chose de plus propre et partageable.
Le projet a évolué en deux versions.
Version 1
Un prototype technique pour tester l’utilisation d’API et de bases de données en PHP from scratch, avec un design minimaliste sur fond sombre. Cette version n’est plus accessible, pour le coup.
Version 2
Une refonte avec un design plus abouti, plus de fonctionnalités, et un code nettoyé. Le projet était fini et utilisable, mais au moment où je l’ai terminé, l’Overwatch League a sorti sa propre solution de paris, ce qui m’a un peu découragé de continuer, évidemment.
Ce que j’ai retenu
Le timing, c’est crucial. Un projet peut être techniquement réussi et perdre son intérêt si la plateforme officielle sort la même chose. C’est aussi un projet qui m’a beaucoup appris sur le développement PHP, la gestion de base de données, et le refactoring entre deux versions. Notamment sur le fait qu’il vaut mieux jeter et refaire que de laisser vivre un prototype qui n’était pas prévu pour durer.
Contexte
Projet personnel, développé pour animer les soirées esport entre amis.
Technologies utilisées
-
PHP (sans framework)
-
JavaScript
-
MySQL
Domopack, un configurateur de maison connectée
Application web de configuration de maison domotique, inspirée des configurateurs de PC et de voitures.
Le projet
Domopack, c’est un service web permettant de composer sa maison connectée en sélectionnant des solutions domotiques à la carte, un peu comme un configurateur de PC ou de voiture. L’idée germait dans ma tête depuis plusieurs mois, du coup ce projet universitaire en 1ère année de licence m’a donné l’occasion de la concrétiser techniquement.
Mes contributions
-
Maquette graphique.
-
Développement du configurateur domotique.
-
Création des différentes pages du site.
Ce que j’ai retenu
C’était ma première réalisation en équipe sur du développement web, et j’ai adoré, pour le coup. Nous avons livré une version finale, stable et sécurisée dans les temps, ce qui était évidemment loin d’être gagné d’avance en première année.
Contexte
Projet universitaire (1ère année de licence), et en même temps un test d’une idée de startup qui me trottait dans la tête.
Technologies utilisées
-
PHP (sans framework)
-
JavaScript / jQuery
GesPatApp, la gestion d’un centre de santé en Java
Application Java de gestion d’un centre de santé, premier projet de développement en équipe.
Le projet
Dans le cadre de ma 1ère année de licence Informatique, nous avons développé une application de gestion d’un centre de santé en Java, sans base de données : tout était stocké dans des fichiers. Une contrainte un peu old school, mais qui force à comprendre ce qui se passe sous le capot de la persistance, notamment quand on écrit à la main le sérialisation.
En binôme, nous avons couvert l’ensemble du cycle de développement.
Mes contributions
-
Maquette graphique de l’interface.
-
Développement du système de stockage par fichiers.
-
Développement des fonctionnalités de gestion (patients, rendez-vous, etc.).
-
Intégration de la maquette dans l’application.
Ce que j’ai retenu
C’était mon tout premier projet de développement, de surcroît en équipe. Malgré l’inexpérience, pour le coup, nous avons livré un logiciel fonctionnel dans les délais impartis, ce qui était une belle fierté, évidemment.
Contexte
Projet universitaire pour l’université de Tours.
Technologies utilisées
- Java (Vanilla)
DreamTeam, un journal de bord de projet terminal
Site WordPress créé pour suivre et documenter l’avancement d’un projet de terminale STI2D.
Le projet
Dans le cadre de ma formation STI2D au lycée, j’ai monté un site web servant de journal de bord pour documenter l’avancement de notre projet de terminale et partager nos progrès avec les évaluateurs. C’est un peu le premier vrai projet perso où j’ai dû tenir quelque chose dans la durée, pour le coup.
Contexte
Projet de terminale STI2D, c’est-à-dire le premier site web que j’ai créé dans un cadre scolaire, et plus largement, un des premiers tout court.
Technologies utilisées
- WordPress
Clique pour ouvrir une app
On discute ?
Un signal à creuser ?
Projet data à cadrer, dataset à explorer, question ouverte. Je lis chaque message.